The OpenEarth philosophy aims to collect and disseminate environmental and lab data sets in a project-superseding manner rather than on a project-by-project basis. We believe that science and engineering have become so data-intensive that data management is beyond the capabilities of individual researchers. Data management needs to migrate from artisanal methods to 21st century technology. This implies data management needs to team up with IT-professionals, and v.v.. This belief is wide-spread, and is called the 4th paradigm. We recommend to read the 4th paradigm book![]() . It illustrates the spreading belief that all sustainable solutions to manage data should be web-based and involve communities. OpenEarth aims to be a 4th paradigm workflow solution to let scientist and engineers collaborate in communities over the web. The need for teaming up science and IT is clearly illustrated in the Nature article
. It illustrates the spreading belief that all sustainable solutions to manage data should be web-based and involve communities. OpenEarth aims to be a 4th paradigm workflow solution to let scientist and engineers collaborate in communities over the web. The need for teaming up science and IT is clearly illustrated in the Nature article![]() . At the bottom of this page you can see a movie of the community activity in our raw data repository, a tool we got from the IT-world. Such communities should not only deal with data, but deal with numerical models and analysis tools as well. Data cannot be treated separately from the rest of science. Therefore OpenEarth aims to be an integral workflow for data, models and tools. For hosting such a the workflow we advocate collaboration with professional data centres such as 3TU datacentre
. At the bottom of this page you can see a movie of the community activity in our raw data repository, a tool we got from the IT-world. Such communities should not only deal with data, but deal with numerical models and analysis tools as well. Data cannot be treated separately from the rest of science. Therefore OpenEarth aims to be an integral workflow for data, models and tools. For hosting such a the workflow we advocate collaboration with professional data centres such as 3TU datacentre![]() , DANS
, DANS![]() and Pangea
and Pangea![]() . Some data centers are member of DataCite
. Some data centers are member of DataCite![]() , and can give you DOI
, and can give you DOI![]() for published data under conditions, enabling anyone to cite your web-based data.
for published data under conditions, enabling anyone to cite your web-based data.
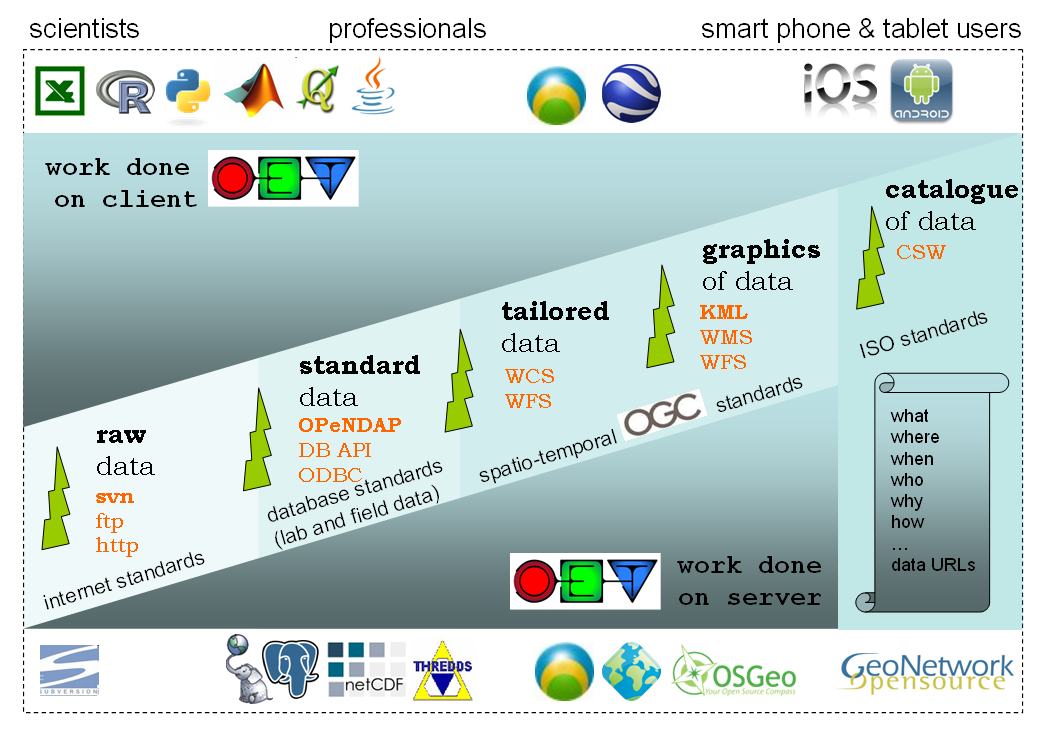
To be an effective and sustainable 4th paradigm solution, OpenEarth has identified the most promising international standards for exchange of data over the web. These standards come from different realms. These standards are shown in the scheme below. We aim to work with all of these standards, but currently only use the bold ones on a daily basis. These include subversion![]() to store not only the raw data, but also the processing software (scripts, settings) under version control using the web 2.0 Wikipedia approach: everyone can sign up for write access. This allows us to naturally attribute versions to data, an aspect that lacks in most of today data management solutions (known as provenance). For standardized data we use the netCDF
to store not only the raw data, but also the processing software (scripts, settings) under version control using the web 2.0 Wikipedia approach: everyone can sign up for write access. This allows us to naturally attribute versions to data, an aspect that lacks in most of today data management solutions (known as provenance). For standardized data we use the netCDF![]() format (NASA and OGC standard). With the CF
format (NASA and OGC standard). With the CF![]() vocabularies and EPSG codes1
vocabularies and EPSG codes1![]() ,2
,2![]() this becomes a very powerful data stack as described in an OceanObs'09 paper
this becomes a very powerful data stack as described in an OceanObs'09 paper![]() . We place the netCDf files on a THREDDS
. We place the netCDf files on a THREDDS![]() OPeNDAP
OPeNDAP![]() server for dissemination of TBs of netCDF data over the web. OPeNDAP is available in many user software applications. It is for instance built-in for MATLAB since 2012, and it is optionally available for the R
server for dissemination of TBs of netCDF data over the web. OPeNDAP is available in many user software applications. It is for instance built-in for MATLAB since 2012, and it is optionally available for the R![]() , python
, python![]() , ArcGis
, ArcGis![]() and many other netCDF programs3
and many other netCDF programs3![]() ,4
,4![]() .
.
For ecological data, which have an overwhelming amount of meta-data, we use a plain-vanilla Relational DataBase Manegement System (RDBMS). We chose the powerful, open source PostgreSQL![]() implementation with PostGIS
implementation with PostGIS![]() spatio-temporal add-on. We are working on adopting dedicated spatio-temporal standard as well. These standard allow for live server-side processing on the data to meet the demands of the user. They deliver tailored data. The OGC consortium
spatio-temporal add-on. We are working on adopting dedicated spatio-temporal standard as well. These standard allow for live server-side processing on the data to meet the demands of the user. They deliver tailored data. The OGC consortium![]() is the international body for specifications of these standards. The EU INSPIRE
is the international body for specifications of these standards. The EU INSPIRE![]() directive prescribes these standards. For typical GIS data (flat, 2D or 2.5D) we already work with postgis
directive prescribes these standards. For typical GIS data (flat, 2D or 2.5D) we already work with postgis![]() , geoserver
, geoserver![]() and geonetwork
and geonetwork![]() . However, these so-called
. However, these so-called WxS protocols still lack implementation in operational software for many specific demands of time-dependent, 3D, curvi-linear data products in our field. We do not develop WxS software ourselves, but just wait for the open source implementations, most under OSGeo![]() umbrella, to cover the demands of our our field. By far the most promising
umbrella, to cover the demands of our our field. By far the most promising WxS client and server implementation we indentified is ADAGUC![]() by the Dutch met office KNMI. ADAGUC not only implemented the WCS standard to request data over the web very fast, but also the WMS standard to request imagery. For exchange of graphics of data, we chose to start working with the KML standards, the standard behind Google Earth that was also adopted as standard by OGC, but we will adopt WMS as well.
by the Dutch met office KNMI. ADAGUC not only implemented the WCS standard to request data over the web very fast, but also the WMS standard to request imagery. For exchange of graphics of data, we chose to start working with the KML standards, the standard behind Google Earth that was also adopted as standard by OGC, but we will adopt WMS as well.
| Unknown macro: {lozenge} OpenEarth data collection protocol |
| Unknown macro: {lozenge} Store your raw data here (Step 1) |
| Unknown macro: {lozenge} Access using OpenDAP protocol THREDDS |
| Unknown macro: {lozenge} Access using OpenDAP protocol THREDDS only |
| Unknown macro: {lozenge} Data in Google Earth |
| Unknown macro: {lozenge} Access data using the WMS and WFS services |
| Unknown macro: {lozenge} Meta-data with map overview data using the WCS services |
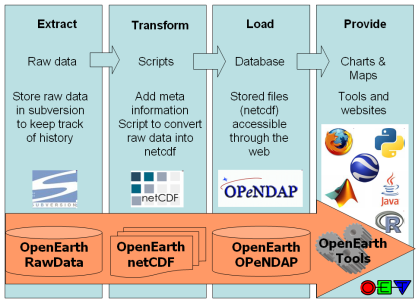
The data collection procedure and the relation between those standards is explained in the [OpenEarth Data Standards] document, developed in the framework of the EU FP7 Project MICORE anfd Building with Nature. The basis the 3-step ETL procedure well-known in the database world. ETL describes the process to Extract data from somewhere, Transform it to the strict database datamodel requirements, and Load it into the database. We extend ETL with one crucial extra step: provide the data to users via the web. We believe that any effective data management solution should include the user both at the start of the ETL process and and the end. Loading data into the database and using data from the database should be possible from the work environment of the user. In the sketch above we explicitly included client and server to highlight the paramount importance of easy and immediate web-based Provide mechanisms of the data, that are not covered by ETL.
ETL contains the followings steps:
- data is not just numbers and meta-information, but consists of raw data produced by the measuring equipment (e.g. volts) + processing scripts.
- raw data + scripts should be stored in the OpenEarthRawData repository enabling version control
- raw data should then be enriched with metadata and processed into useful data products (netCDF, PostgreSQL table) using transformation scripts that should also be put under version control in a repository
- resulting data products should conform to the best open source semantic standards available, e.g. CF
 , WoRMS
, WoRMS - data products should be made available easily via webbased interfaces (OPeNDAP, ODBC ore dedicated DB-APIs, WxS) but also with automatable procedures for widely-used data processing languages such as matlab, IDL, python, fortran, C and java (OpenEarth Tools).
- data products are primarily meant for dissemination, raw data and scripts are primarily meant for archiving.
- meta-data should be gathered and inserted into a central catalogue.
Numerous other datasets have been or are being uploaded continually in the MICORE and Building with Nature research programmes. And OpenEarth is not the only initiative to share and disseminate government-paid Earth science data freely on the web using open standards. We made an inventory of related initiatives. Our aim is to spread the use of the open standards and make them stick in our everyday work.
<object width="425" height="344"><param name="movie" value="http://www.youtube.com/v/7w2DBazX6g4&hl=en&fs=1"></param><param name="allowFullScreen" value="true"></param><param name="allowscriptaccess" value="always"></param><embed src="http://www.youtube.com/v/7w2DBazX6g4&hl=en&fs=1" type="application/x-shockwave-flash" allowscriptaccess="always" allowfullscreen="true" width="425" height="344"></embed></object>