Introduction to secondary validation SpatialHomogeneityCheck
Overwrites the flag of the timeseries with unreliable or doubtful when the estimation of the value based on neighbouring values differs too much from the observed value. The criteria for that can be specified to be a maximum threshold or relative (i.e. percentage of the standard deviation) or both. The estimation is based upon a maximum number of closest by other locations within a maximum search radius.
The purpose of this check is to update the flags of the output timeseries whenever the error exceeds the specified threshold. The error is defined by the difference between the value and the estimation which is the average of the values from the selected neighbouring locations weighted for distance. Note that the check suppports non-equidistant comparison where timesteps should be within the same fixed range +/- 500 milliseconds.
During the check, the threshold criteria for the check are first sorted. Unreliability before doubtful and absolute before relative. The first worst case result will be applied and logged. This means that when exceedances for all four checks need to be logged then it is required to specify the four checks individually. In the latter case, the state of the flags result will not always be the same, since the result also depends on the flags, e.g. if the first test alters the flag, the next check has different input.
The estimation formula used:

where:
Pest(t) is the estimated value at the test station at time t
Pi(t) is the measured value at neighbour station i at time t
Di is the distance between the test station and the neighbour station i
N is the number of neighbour stations taken into account
b is the power of distance D, (default b=2)
Test criteria
The test criterion with an absolute threshold is exceeded when the following condition fails:
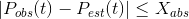
The test criterion with relative threshold is exceeded when the following condition fails:

with:
b the admissable absolute difference
Xrel the multiplier of the standard deviation
SPest(t)
the standard deviation of neighbouring values
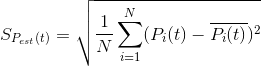
Notes on implementation
Current implementation does not directly use the output time series in calculating the error. Instead to obtain the observed value Pobs it looks at the input time series for the same location as the output time series.
This is because it enables changing the flag of a time series with different parameters / units compared to the input.
In order for this to work correctly, the locations / location set of the input and output time series must be the same.
Configuration
- id: identifier of the check.
- variableDefinition: embedded variable definition (see above).
- inputVariableId: One or more identifiers for variables of which the flags have to be used.
- outputVariableId: One or more identifiers for variables for which the flags have to be modified.
- searchRadius: The maximum radius for selecting reference locations in meters.
- distancePower: Power of distance, default is 2.
- distanceGeoDatum: The Geo Datum with which to determine the distances between the locations. This must be a sensible Geo Datum using meters and rectangular grid cells, and all locations should be able to fit in.
The search algorithm can be speeded up by using a limited set of neighbouring locations.
- numberOfPoints: The maximum number of neighbouring locations to base the estimation on. The neighbouring locations are established once per check. Missings are ignored. Default is 8.
- numberOfBackupPoints: The maximum number of backup locations. The backup locations are established once per check. When some of the neighbouring stations contain missings for a certain timestep,
then the values of the nearest backup locations with non-missings will be used instead.
Alternatively, it is possible to divide the search for neighbouring locations over quadrants which may lead to a more balanced set the neighbouring locations. To do so use the following configuration instead of numberOfPoints and numberOfBackupPoints.
- numberOfPointsPerQuadrant: Same as numberOfPoints, except now the locations per quadrant The maximum number of neighbouring locations to base the estimation on. The neighbouring locations are established once per check. Missings are ignored.
- numberOfBackupPointsPerQuadrant: The maximum number of backup locations. The backup locations are established once per check. Suppose two of the neighbouring stations contain missings for a certain timestep, then the values of two backup nearest backup locations with non-missings will be used instead.
The x-, y- and z-components used within the distance function that yield the neighbouring stations can be normalized. This can be useful for influencing the distance function for differences in elevation of neighbouring stations. The following multipliers can be used for this purpose:
- xMultiplier: multiplies the difference on the x-axis by this factor within the distance function. Default is 1.
- yMultiplier: multiplies the difference on the y-axis by this factor within the distance function. Default is 1.
- zMultiplier: multiplies the difference on the z-axis by this factor within the distance function. Default is 0.
For each threshold,
- absolute or relative (or both since 2019.02) Compares theshold with absolute value, or relative factor times the standard deviation.
- appliesWhenWeightedNeighbors (since 2019.02) choose whether the weighted neighbors should be higher, lower or higherOrLower
- outputFlag: Output flag for values of output variables that exceed the specified threshold. (unreliable or doubtful)
- outputMode: When this option is set to logs_only, the flags will not be updated but the log events will be generated.
- sourceId: Fine grained id for indicating which check caused the flag to be altered. In this case these sourceIds must be specified in the regionConfig (CustomFlagSources.xml).
- logLevel: Log level for the log message that is logged if a time series does not pass the check. Can be DEBUG, INFO, WARN, ERROR or FATAL. If level is error or fatal, then the module will stop running after logging the first log message. Fatal should never be used actually.
- logEventCode: Event code for the log message that is logged if a time series does not pass the check. This event code has to contain a dot, e.g. "TimeSeries.Check", because the log message is only visible to the master controller if the event code contains a dot.
- logMessage: Log message that is logged if a time series does not pass the check. Some more options are available than in the other checks:
Tag | Replacement |
|---|---|
%AMOUNT_CHANGED_FLAGS% | The number of flags that has been altered. |
%CHECK_ID% | The id of the check that caused the flags to be altered. |
%HEADER% | The header names of the timeseries for which the flags were altered. |
%LOCATION_ID% | The locationId where the alterations took place. |
%LOCATION_NAME% | The name of the locations where the alterations took place. |
%OUTPUT_FLAG% | The flag that has been set. |
%PARAMETER_ID% | The parameterId where the alterations took place. |
%PARAMETER_NAME% | The name of the parameter where the alterations took place. |
%PERIOD% | The period in which flags were changed. |
%NONE% | Hide the autogenerated location and period in the log message. |
Rules for updating the flags
For each timestep, the most unreliable flag in the inputVariables is determined, e.g. unreliable > doubtful > reliable.
If the most unreliable flag in the inputVariables is unreliable, and the corresponding flag in the outputVariable is reliable or doubtful, it is made unreliable as well.
If the most unreliable flag in the inputVariables is doubtful, and the corresponding flag in the outputVariable is reliable, it is made doubtful as well.
OutputSpatialMean and OutputSpatialStandardDeviation
Internally the SpatialHomogeneityCheck uses a spatially weighted mean and weighted standard deviation using the neighbouring locations. These intermediate values are used for deciding whether or not the threshold criteria have been met and the flags need updated. Since 2013.01 it is possible to write these values to the datastore using the options outputSpatialMean and outputSpatialStandardDeviation.
Configuration examples for spatialHomogeneityCheck
A configuration example for the spatialHomogeneityCheck is given below:
<?xml version="1.0" encoding="UTF-8"?> <secondaryValidation xmlns="http://www.wldelft.nl/fews" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.wldelft.nl/fews http://fews.wldelft.nl/schemas/version1.0/secondaryValidation.xsd"> <variableDefinition> <variableId>spatialHomogeneityCheck_location1</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location1</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location2</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location2</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location3</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location3</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location4</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location4</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location5</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location5</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location6</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location6</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location7</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location7</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location8</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location8</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location9</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location9</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location10</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location10</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <variableDefinition> <variableId>spatialHomogeneityCheck_location11</variableId> <timeSeriesSet> <moduleInstanceId>SpatialHomogeneityCheck</moduleInstanceId> <valueType>scalar</valueType> <parameterId>H.obs</parameterId> <locationId>location11</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="minute" multiplier="15"/> <readWriteMode>read complete forecast</readWriteMode> </timeSeriesSet> </variableDefinition> <spatialHomogeneityCheck id="spatialHomogeneityCheck"> <input> <variableId>spatialHomogeneityCheck_location1</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location2</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location3</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location4</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location5</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location6</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location7</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location8</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location9</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location10</variableId> </input> <input> <variableId>spatialHomogeneityCheck_location11</variableId> </input> <searchRadius>100000</searchRadius> <numberOfPoints>4</numberOfPoints> <distancePower>2</distancePower> <threshold> <absolute>3</absolute> <outputFlag>unreliable</outputFlag> <logLevel>WARN</logLevel> <logEventCode>SecondaryValidation.spatialHomogeneityCheck</logEventCode> <logMessage>%AMOUNT_CHANGED_FLAGS% flags set to %OUTPUT_FLAG% by %CHECK_ID%, header=%HEADER%, location(s)=%LOCATION_NAME%</logMessage> </threshold> <threshold> <relative>2</relative> <outputFlag>doubtful</outputFlag> <logLevel>INFO</logLevel> <logEventCode>SecondaryValidation.spatialHomogeneityCheck</logEventCode> <logMessage>%AMOUNT_CHANGED_FLAGS% flags set to %OUTPUT_FLAG% by %CHECK_ID%, header=%HEADER%, location(s)=%LOCATION_NAME%</logMessage> </threshold> <output> <variableId>spatialHomogeneityCheck_location1</variableId> </output> <output> <variableId>spatialHomogeneityCheck_location3</variableId> </output> <output> <variableId>spatialHomogeneityCheck_location5</variableId> </output> <output> <variableId>spatialHomogeneityCheck_location7</variableId> </output> <output> <variableId>spatialHomogeneityCheck_location9</variableId> </output> <output> <variableId>spatialHomogeneityCheck_location11</variableId> </output> </spatialHomogeneityCheck> </secondaryValidation>