Introduction
The archive admin console can be used for the following tasks:
- verifying the status of the archive,
- start and stop archive tasks,
- archive configuration.
The web pages which are available for these tasks will be explained below.
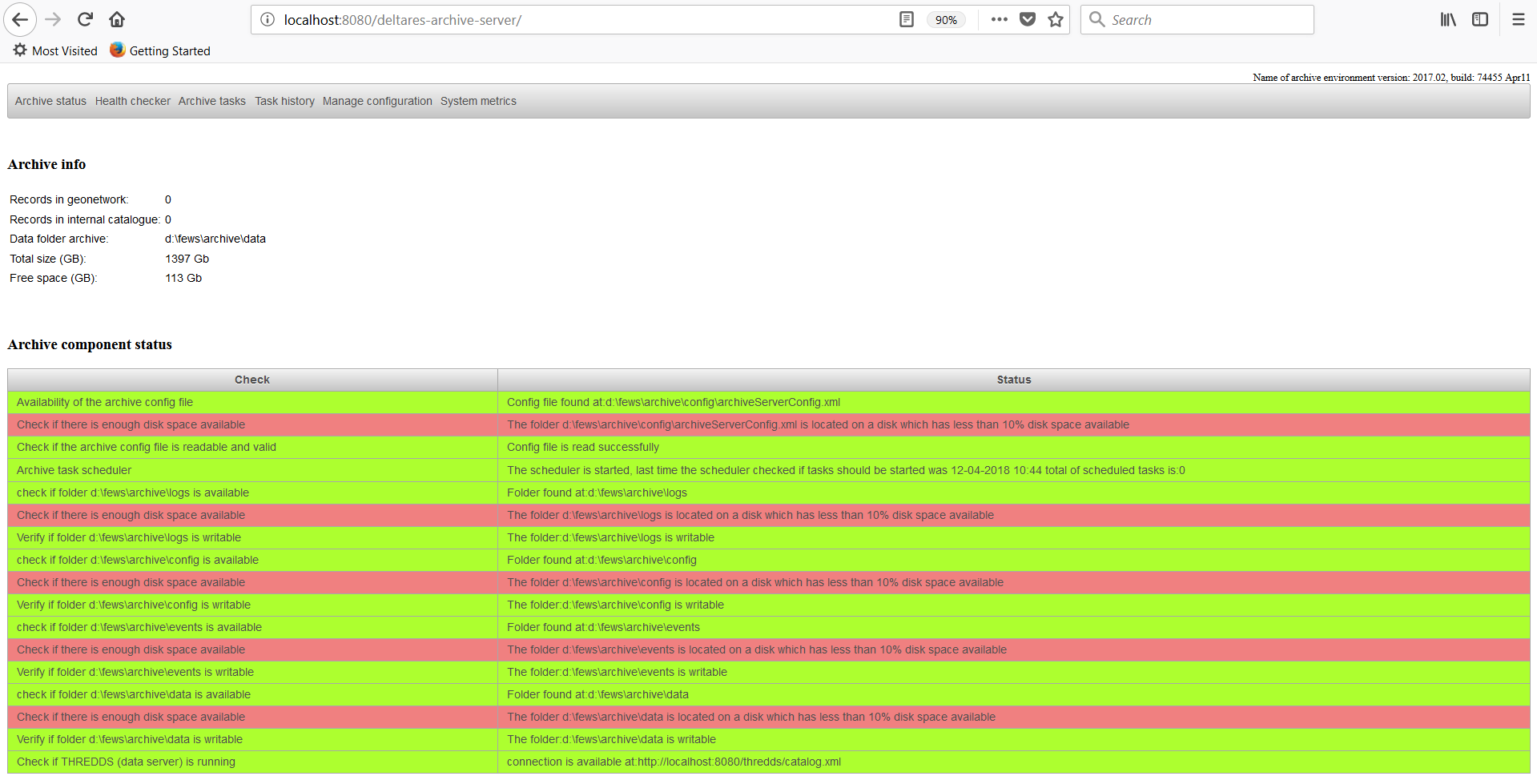
Archive Status
The archive admin console provides an overview of the current status of the archive with the display "status archive". This display is the default page which the user sees when the admin console is accessed by
a web browser. The top section "Archive info" shows how many records are available in the catalogue, the current data folder and how much disk is available and used.
In addition the total amount of space and free space on disk is shown.
The lower section "Archive component status" shows the current status of the archive. If a problem is detected with the archive this will be shown in the section below.
All checks should be green. If you see that one of the checks is failing, please notify your system administrator about the detected problem.
Health Checker
The tab health checker shows an overview of all the build-in checks which are available for the Archive.
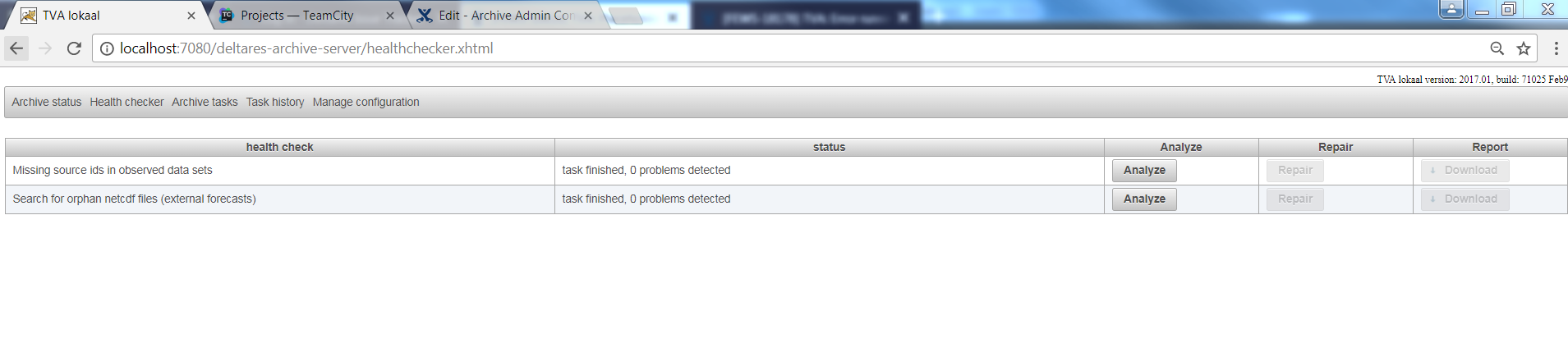
Running a health check is always a two step process.
First step is to run the analysis. In this step the health check will verify if a problem exists in your archive.
To run the analysis for a certain health check simply press the analyze button for a specific health check.
After the analysis is done the status field will show how many (if any) problems were found. More detailed information can be found by downloading the report.
If the analysis has found problems the download button in the report column will be enabled and will allow the user to download a file containing more detailed information about the problems found.
After reviewing the report the actual repair can be done. In this step the health check will repair the found problems. To start the repair action (this can only be done after the analysis has run and found problems!) press the Repair button in the repair column. After the repair is finished the results of the repair should be reviewed by verifying the changed files in the archive.
It is always possible to fallback to the situation prior to the repair. In the root folder of the archive a folder HealthChecker will be created. This folder will contain a backup of the files which were changed during the repair action. The files are copied with their relative path to the data folder. A meta data file in folder /opt/fews/archive/data/2017/01/area/01/ will be backuped to folder /opt/fews/archive/HealthChecker/<health check id>-<datetime)/2017/01/01/area/01.
Remember that you always have to run the harvester to make the changes made in your meta data files available in the catalogue.
The following healh checks are available
Missing source ids in observed data sets
It is possible to assign a source to a netcdf-file containing observed data. In some cases some netcdf-files don't have a source id assigned while other netcdf-files with the same file name have a source id assigned.
This can happen if, for example, the source id was added to the data export while the data export has already been running operationally for some time. In this case the already exported netcdf-files won't have the source id assigned while the newly exported files will have source id assigned. This tool will determine first how the netcdf-files are mapped to source ids. If the netcdf-files with file name A always have source id X assigned or don't have a source id the following will be done. The netcdf-files without a source id will automaticly have source id X assigned. This will be done by added the source id to the meta data files.
Search for orphan netcdf files (external forecasts)
At the end of 2017 the following bug was found in the data export for external forecasts. External forecast will have an incorrect meta data file if the data set contains more than 1 netcdf-file. The bug in export caused that only the last exported netcdf-file was listed in the meta data file. This health check will detect this problem and fix it.
This health check only works for scalar time series at this moment.
Archive tasks
The page Archive Tasks can be used to start and stop archive tasks. It also possible to see which tasks are scheduled and what their task schedule is.
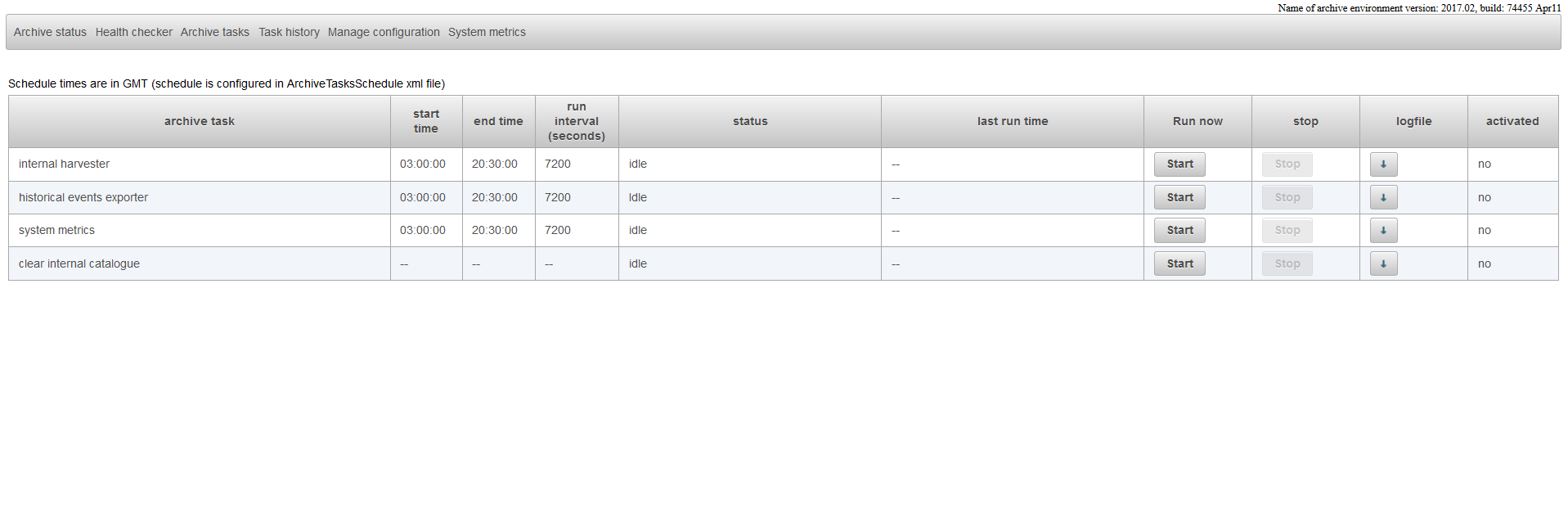
This page shows an overview of the tasks which are configured for the archive. The configuration of the archive tasks can be done by adjusting the ArchiveTaskSchedule.xml.
Detailed information about the configuration of this file can be found here:Configuration of the Delft-FEWS Archive Server
The archive has two types of tasks.
- tasks which run periodically,
- tasks which cannot be scheduled but which can only run manually.
Tasks which can be scheduled have a start time, an end time and a run interval. The start time and end time indicate the time window in which the task is allowed to run.
The run interval shows how often the task should run. A scheduled task only runs periodically if it is activated. The last column "activated" shows if the task is activated or not.
Tasks can be activated or deactivated by changing the configuration. More details can be found here:Configuration of the Delft-FEWS Archive Server
A task can be started manually by pressing the start-button. Some tasks can only be started if there is no other tasks of the same group to which it belongs is running.
The internal harvester can, for example, only run if the clear catalogue task is not running. If the clear catalogue task is running the start button of the internal harvester task will be disabled.
The tasks "internal harvester" and the task "clear internal catalogue" are the two most important and most used tasks of the archive.
The task "internal harvester" is responsible for updating and maintaining the catalogue. The catalogue is used to find data sets in the archive.
The second task "clear internal catalogue" is used clear the entire catalogue. When you run the task the entire catalogue will be empty!
You will have to run the task "internal harvester" again to rebuild the catalogue.
The are a lot of other tasks available: More details can be found here:Configuration of the Delft-FEWS Archive Server
Custom tasks
It is also possible to define custom tasks. Below an example.
<scheduledArchiveTask> <customArchiveTask> <archiveTaskId>myTask</archiveTaskId> <executableFile>d:\fews\archive\config\script.exe</executableFile> <logFile>d:\fews\archive\config\log</logFile> </customArchiveTask> <description/> <startTime>03:00:00</startTime> <endTime>09:00:00</endTime> <runInterval>2</runInterval> <active>true</active> </scheduledArchiveTask>
To make sure that the archive can start the script correctly, you can start the script from the commandline and check if it runs correctly. Usually configurators create a .bat-file or a .sh file to launch another executable.
Task History
The page task history shows when certain archive tasks were started and when they were finished. The page also indicates if the tasks was finished succesfully or not.
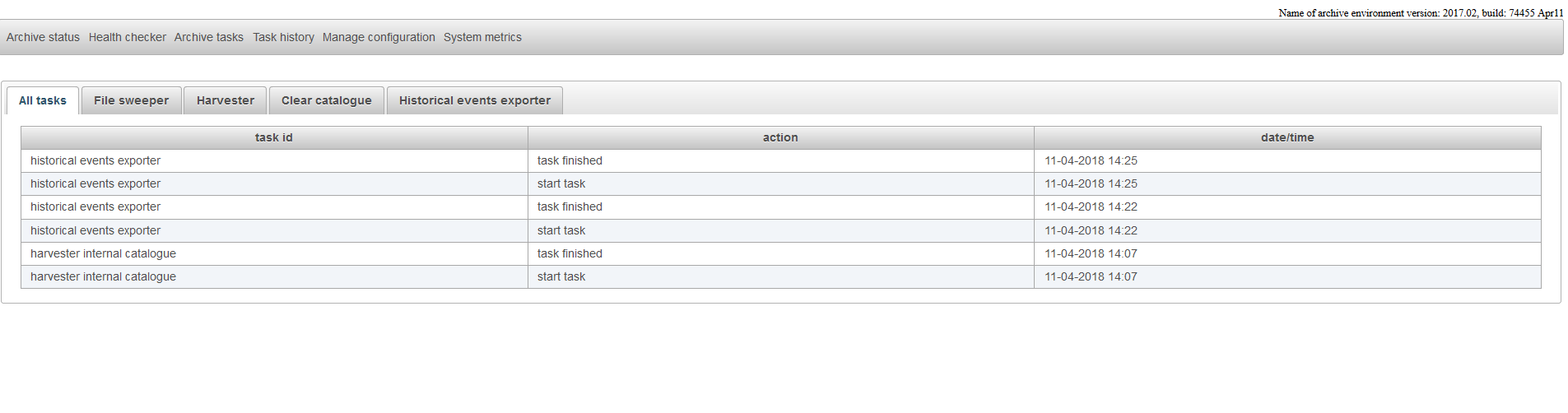
For the standard tasks like file sweeper, harvester, clear archive and the historical events exporter there is a tab available for each task. Custom defined tasks are shown in the tab custom
Manage configuration
The display "manage configuration" allows the configurator to download configuration files, change them manually on their own pc and upload the changed configuration files to the archive server.
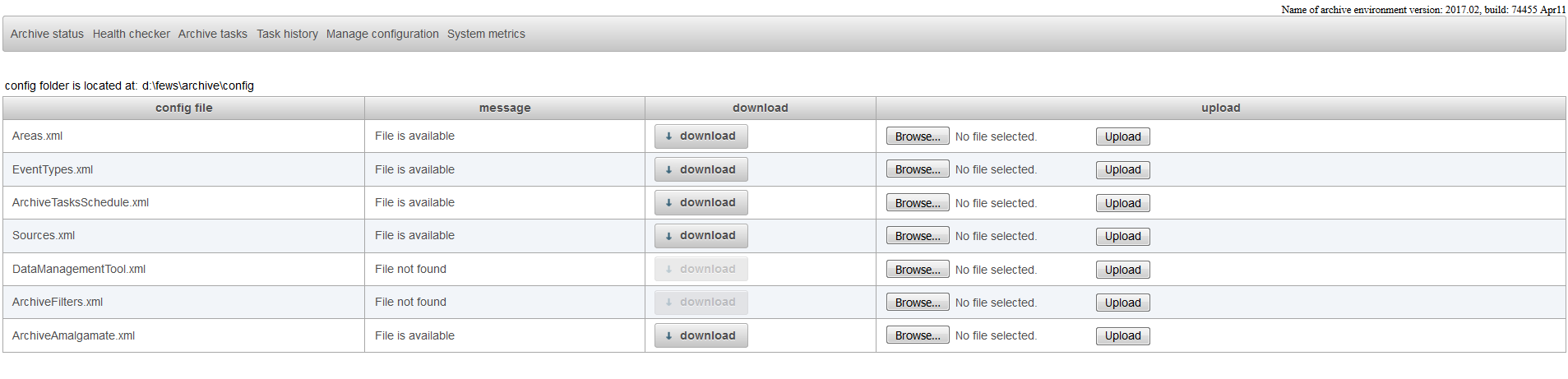
When an invalid file is uploaded to the archive server this will be detected by the system and the file will not be used.
System Metrics
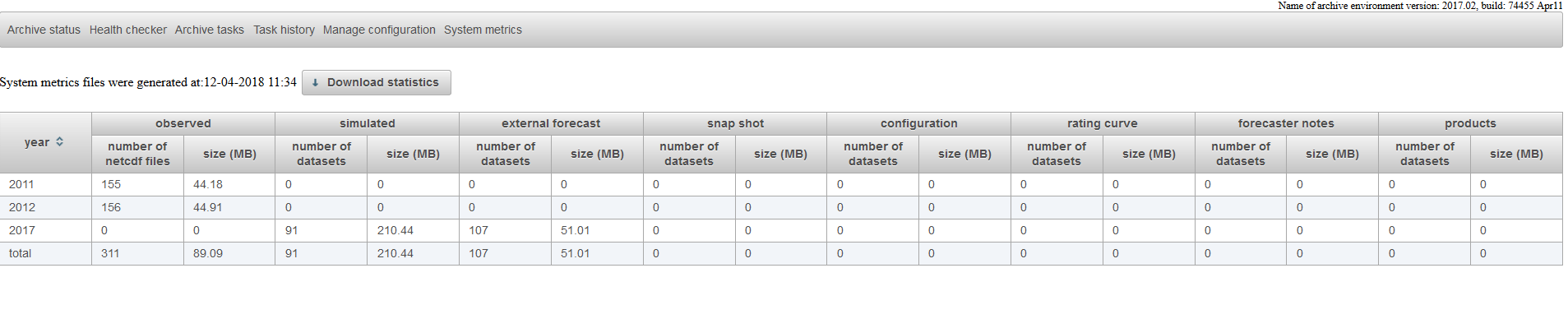
The page System Metrics shows how many netcdf-files or data sets are available for the different data types which are stored in the archive.
In addition it shows how disk space is used for a certain year by a certain data type in in the archive. More detailed statistical information can be downloaded by using
the Download statistics button. The system metrics are calculated by the system metrics task. Make sure that you have configured this task and that it has run recently if you want to have up-to-date information in this page.
Data management
The archive admin console provides tools to manage the data in the archive. To prevent that the amount of the data in the archive keeps growing several tools are available which can be used to remove expired data sets from the archive. This section will explain how to confgure and use these tools.
First step is to define the rules for expiring data sets. The file DataManagementTool.xml can be used to define the rules for expiring data sets.
Below is an example given of this file.
<arc:dataManagementTool xmlns:arc="http://www.wldelft.nl/fews/archive" xsi:schemaLocation="http://www.wldelft.nl/fews/archive http://fews.wldelft.nl/schemas//version1.0/archive-schemas/dataManagementTool.xsd" xmlns="http://www.wldelft.nl/fews/archive" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <outputFile>d:\fews\output\managementreport.csv</outputFile> <backupFolder>d:\fews\data_to_tape</backupFolder> <!-- required when using the predefined remove-data-from-archive task--> <lifeTimeRules> <defaultLifeTime unit="year" multiplier="10"/> <defaultAction>default</defaultAction> <!-- optional from 2020.01 onwards, only relevant when using custom tasks that require such action field--> <lifeTimeSimulatedDataSets> <lifeTime unit="year" multiplier="15"/> <action>remove</action> <!-- optional from 2020.01 onwards, only relevant when using custom tasks that require such action field--> </lifeTimeSimulatedDataSets> <lifeTimeObservedDataSets> <lifeTime unit="year" multiplier="15"/> <action>remove</action> <!-- optional from 2020.01 onwards, only relevant when using custom tasks that require such action field--> </lifeTimeObservedDataSets> </lifeTimeRules> </arc:dataManagementTool>
This example contains all the mandatory elements of this file. The output file defines were the data management tool should write its output. The output will be the list of data sets which are expired according the defined rules. As of release 2020.01, the action element is optional and only required if a customTask requires this field in the resulting managementreport.csv. The predefined remove-data-from-archive task neglects the action element. When using the predefined remove-data-from-archive task, the backupFolder is needed as data to be removed from the archive is moved to
The default life time defines the life time of a data set in the archive when there is not a more specific rule defined. In the example above there is no rule defined for external data sets. This means that the default life time will be used for external data sets. For simulated data sets there is a specific rule defined in the tag lifeTimeSimulatedDataSets. This means that for simulated data sets the default life time will not be used but the more specific rule in the lifeTimeSimulatedDataSets. If needed it is possible to define specific rules for the other types of data sets in the archive like external forecasts, rating curves, configuration etc. An example is given below.
<arc:dataManagementTool xmlns:arc="http://www.wldelft.nl/fews/archive" xsi:schemaLocation="http://www.wldelft.nl/fews/archive http://fews.wldelft.nl/schemas//version1.0/archive-schemas/dataManagementTool.xsd" xmlns="http://www.wldelft.nl/fews/archive" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <outputFile>d:\fews\output\managementreport.csv</outputFile> <lifeTimeRules> <defaultLifeTime unit="year" multiplier="10"/> <defaultAction>default</defaultAction> <lifeTimeSimulatedDataSets> <lifeTime unit="year" multiplier="15"/> <action>remove</action> </lifeTimeSimulatedDataSets> <lifeTimeObservedDataSets> <lifeTime unit="year" multiplier="15"/> <action>remove</action> </lifeTimeObservedDataSets> <lifeTimeExternalForecastDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeExternalForecastDataSets> <lifeTimeMessagesDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeMessagesDataSets> <lifeTimeConfigurationDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeConfigurationDataSets> <lifeTimeRatingCurveDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeRatingCurveDataSets> </lifeTimeRules> </arc:dataManagementTool>
In the FEWS OC or SA it is possible to define events. It is possible to configure a life time for data sets which belong to a certain event. Data sets which belong to an event are usually more important than other data sets in the same period. By configuring a different life time for data sets which belong to a event it is possible to keep these types of data sets longer in the archive.
An example is given below.
<arc:dataManagementTool xmlns:arc="http://www.wldelft.nl/fews/archive" xsi:schemaLocation="http://www.wldelft.nl/fews/archive http://fews.wldelft.nl/schemas//version1.0/archive-schemas/dataManagementTool.xsd" xmlns="http://www.wldelft.nl/fews/archive" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <outputFile>d:\fews\output\managementreport.csv</outputFile> <backupFolder>d:\fews\backup</backupFolder> <lifeTimeRules> <defaultLifeTime unit="year" multiplier="10"/> <defaultAction>default</defaultAction> <lifeTimeSimulatedDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeSimulatedDataSets> <lifeTimeSimulatedDataSets> <sourceId>sourceId</sourceId> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeSimulatedDataSets> <lifeTimeObservedDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeObservedDataSets> <lifeTimeExternalForecastDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeExternalForecastDataSets> <lifeTimeMessagesDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeMessagesDataSets> <lifeTimeConfigurationDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeConfigurationDataSets> <lifeTimeRatingCurveDataSets> <lifeTime unit="year" multiplier="10"/> <action>remove</action> </lifeTimeRatingCurveDataSets> <eventRule> <eventTypeId>historic event</eventTypeId> <lifeTime unit="year" multiplier="40"/> </eventRule> <eventRule> <eventTypeId>calibration event</eventTypeId> <lifeTime unit="year" multiplier="40"/> </eventRule> <eventRule> <eventTypeId>watercoach event</eventTypeId> <lifeTime unit="year" multiplier="40"/> </eventRule> <eventRule> <eventTypeId>review event</eventTypeId> <lifeTime unit="year" multiplier="40"/> </eventRule> <eventRule> <eventTypeId>flood watch event</eventTypeId> <lifeTime unit="year" multiplier="40"/> </eventRule> </lifeTimeRules> </arc:dataManagementTool>
Once the configuration of the DataManagementTool.xml is finished it should be added to the configuration of the archive server. You can do this by uploading it to the archive.
Select the tab manage configuration and upload the new DataManagementTool.xml to the archive by using the browse (to select the file) and upload button in the row DataManagementTool.xml.
It is also possible to put this config file directly in the config folder of the archive but you will have to restart the tomcat instance of the archive server to make it aware of the fact that there is new file available.
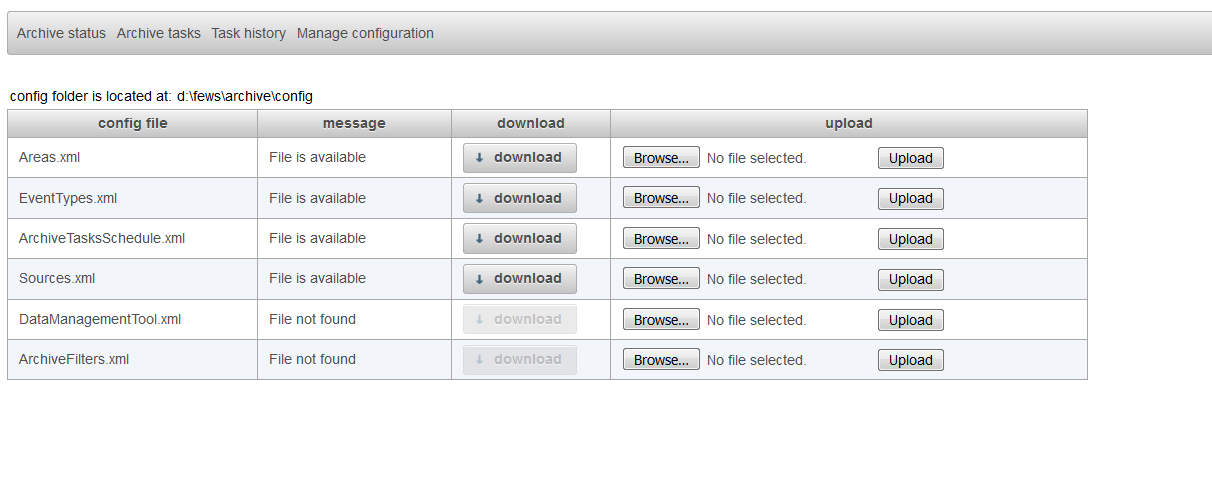
After this step it is possible to run the data management tool to search for expired data sets in the archive. This task should be available as one of the tasks in the archive tasks tab. If it is not available there you should add it to your configuration. Go to the manage configuration tab and download the ArchiveTaskSchedule.xml file. Verify if the preDefinedArchiveTask data management tool is available.
An example is given below.
<manualArchiveTask> <predefinedArchiveTask>data management tool</predefinedArchiveTask> <description>data management tool</description> </manualArchiveTask>
After adding this task you should upload the changed ArchiveTaskSchedule.xml to the archive server in the manage configuration tab.
The task should now be available after selecting the tab archive tasks.
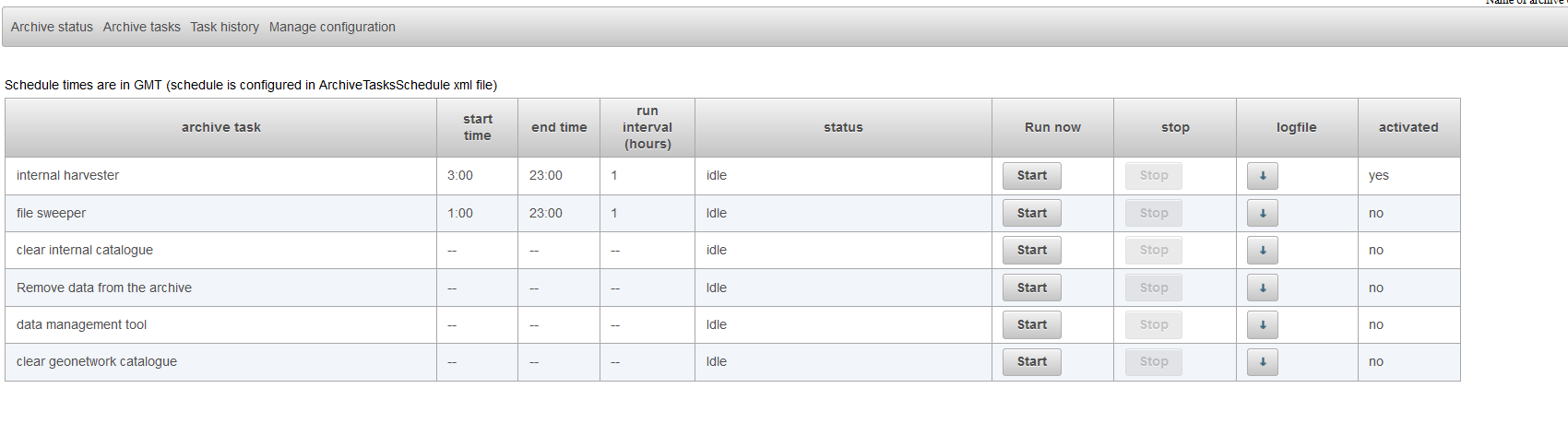
You can start this tool by pressing the start-button. After running this task the output should be available in the output file which is configured in the DataManagementTool.xml. You can download this file in the tab manage configuration.
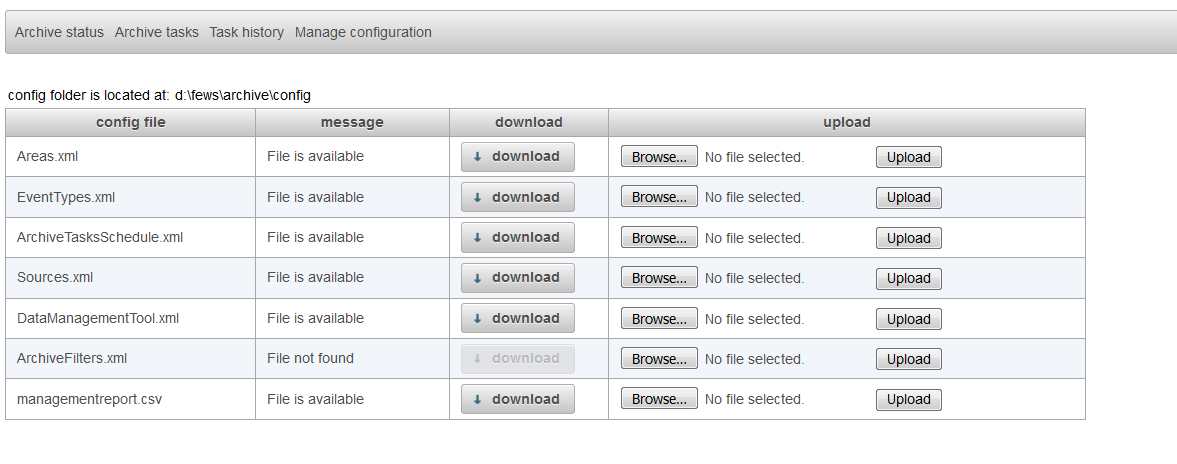
In the screenshot above the you can see that the file managementreport.csv can be downloaded by pressing the download button.
You can download this file by pressing the download button to review which data sets are expired. If needed you can manually edit this file by using a text editor or excel.
After you reviewed and/or changed this file you can upload the changed file to the archive by using the upload button.
The next step is to run the task remove data from archive.
The task remove data from archive will move all the expired data sets which are listed in the output file to the configured backup folder in the DataManagementTool.xml file.
First verify if this task is configured in the ArchiveTaskSchedule.xml file. A preDefinedArchiveTask remove data from archive should be available.
If this task is not available yet you should download the ArchiveTaskSchedule.xml file (you can do this in the manage configuration tab) and add this task to this file.
An example is given below.
<manualArchiveTask> <predefinedArchiveTask>remove data from archive</predefinedArchiveTask> <description>Remove data from the archive</description> </manualArchiveTask>
After uploading this file this task should be available in the Archive Tasks tab. Use the start button to run this task.
The task remove data from archive will move all the files listed in the output file of the data management tool to the configured backup folder in the DataManagementTool.xml.