...
What | nameofinstance.xml | ||
|---|---|---|---|
Description | Configuration for the general adapter module | ||
schema location | httphttps://fewsfewsdocs.wldelftdeltares.nl/schemas/version1.0/generalAdapterRun.xsd | Entry in ModuleDescriptors | <moduleDescriptor id="GeneralAdapter"> |
| Table of Contents |
|---|
| Info | ||
|---|---|---|
| ||
Since 2018.02, the Forecasting Shell and Operator Client software are shipped with a stripped-down JRE with only those java modules that the OC / FSS / CM client needs. This might cause module components such as adapters, forecast models and simulations that were perfectly running fine on the shipped JRE in 2017.02 or earlier to stop from working since additional modules might be required. If this is the case, recommended options are to not try and resolve this in the Forecasting Shell launcher service, but to choose one of the following options:
|
...
- startUpActivities
- exportActivities
- executeActivities
- importActivities
- shutDownActivities
General settings
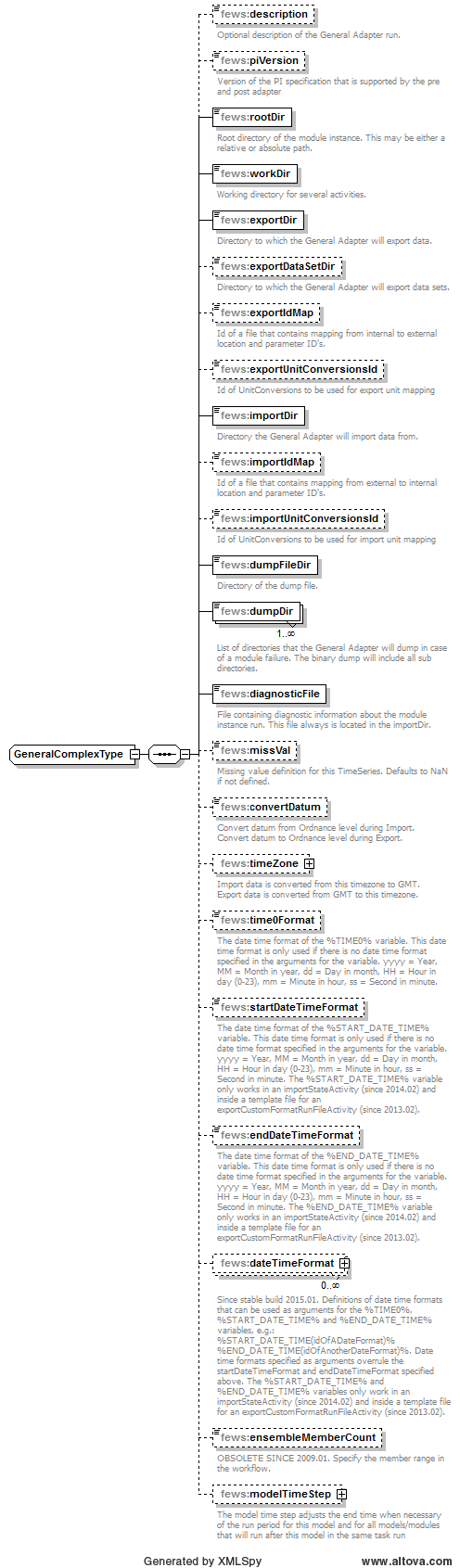
Figure 67 Elements of the general section of the general adapter configuration
...
Version of the PI specification that is supported by the pre and post adapter.

rootDir
Root directory for the external module. Other directories can be defined relative to this rootDir using predefined tags (see comment box below).
workDir
Working directory to be used by the external module. When started this directory will be the current directory.
exportDir
Directory to export data from Delft-FEWS to the external module. All Published Interface files will be written to this directory (unless overruled in naming the specific export files).
exportDataSetDir
Directory to export module datasets from Delft-FEWS to the external module. A module dataset is a ZIP file, which will be unzipped using this directory as the root directory. If the zip file contains full path information, this will be included as a tree of subdirectories under this directory.
updateExportDataSetDirOnlyOnChange
If set to 'true' datasets are only updated when they have changed. Change is detected by comparing the timestamp in the dataset info file with the modification time of the dataset configuration file. By default this value is 'false' and datasets are always updated. Since the 2018.02 the dataset info file is written to $REGION_HOME$/temp/moduleDataSetsCheckSums when the export dir is sub dir (any level) of the region home.
purgeExportDataSetDirOnUpdate
If a dataset has been detected as updated then this option allows user to purge content of existing moduledataset directory before new moduledataset is exported. By default the value is 'false' and all existing dataset content is overwritten.
exportIdMap
ID of the IdMap used to convert internal parameterId's and locationId's to external parameter and location Id's. See section on configuration for Mapping Id's units and flags.
exportUnitConversionsId
Id of UnitConversions to be used for export unit mapping
importDir
Directory to import result data from the external module to Delft-FEWS. All Published Interface files will be read from this directory (unless overruled in naming the specific export files).
importIdMap
ID of the IdMap used to convert external parameterId's and locationId's to internal parameter and location Id's. This may be defined to be the same as the import directory, but may also contain different mappings. See section on configuration for Mapping Id's units and flags.
importUnitConversionsId
Id of UnitConversions to be used for import unit mapping
dumpFileDir
Directory for writing dump files to. Dump Files are created when one of the execute activities fails. A dump file is a ZIP file which includes all the dumpDir directories defined. The dump file is created immediately on failure, meaning that all data and files are available as they are at the time of failure and can be used for analysis purposes. The ZIP file name is time stamped to indicate when it was created.
dumpDir
Directory to be included in the dump file. All contents of the directory will be zipped. Multiple dumpDir's may be defined.
NOTE: ensure that the dumpDir does not include the dumpFileDir. This creates a circular reference and may result in corrupted ZIP files.
diagnosticFile
File name and path of diagnostic files created in running modules. This file should be formatted using the Published Interface diagnostics file specification.
missVal
Optional specification of missing value identifier to be used in PI-XML exported to modules and imported from modules.
NOTE: it is assumed an external module uses the same missing value identification for both import and export data.
convertDatum
Optional Boolean flag to indicate level data is used and produced by the module at a global rather than a local datum. The convention in Delft-FEWS is that data is stored at a local datum. If set to true data in parameter groups supporting datum conversion will be converted on export to the global datum by adding the z coordinate of the location. (see definition of parameters and locations in Regional Configuration).
timeZone
Time zone with reference to UTC (equivalent to GMT) for all time dependent data communicated with the module. If not defined, UTC+0 (GMT) will be used. This time zone is used when importing pi files and the time zone is not available in the pi file.
timeZoneOffset
The offset of the time zone with reference to UTC (equivalent to GMT). Entries should define the number of hours (or fraction of hours) offset. (e.g. +01:00). This time zone is used when importing pi files and the time zone is not available in the pi file.
timeZoneName
Enumeration of supported time zones. See appendix B for list of supported time zones. This time zone is used when importing pi files and the time zone is not available in the pi file.
time0Format
The date time format of the %TIME0% variable and the %CURRENT_TIME% variable. This date time format is only used if there is no date time format specified in the arguments for the variable. yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute.
startDateTimeFormat
The date time format of the %START_DATE_TIME% variable. This date time format is only used if there is no date time format specified in the arguments for the variable. yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute. The %START_DATE_TIME% variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02).
endDateTimeFormat
inMemoryFileTransfer
Since 2022.02. When true all exported and imported files (XML, NetCdf) are transferred in memory between FEWS and execute activities. An execute activity can read the file content from
var input = (BufferedInputStream) System.getProperties().get(file)
and write to
var output = (BufferedOutputStream) System.getProperties().get(file).
All execute activities that transfer files to and from FEWS should be java activities that don't use a custom jre and check the System.getProperties().get(file) before they fall back to read/write the file on disk. All files can be transferred in memory, except NetCDF4. For NetCDF3 files the System.getProperties().get(file) contains a chunked byte array (byte[][]). An empty byte[][] array is set to tell an execute activity to save the nc file to memory as chunked byte array. The diagnostic file is also transferred in memory. Execute activities should always fall back on the files on disk when the System.getProperties().get(file) == null
Adapters that consistently use the Delf-PI.jar classes for I/O of XML data, configuration and diagnostics do not need to be modified to specifically make use of this feature, as the switching between in-memory or on-disk file transfers will be handled by Delf-PI.jar automatically. The feature has also been implemented for NetCDF files in NetCdfUtils.jar but this is considered experimental and requires further testing before using it in production.
Fortran/C models has to be recompiled to so/dll to allow in memory transfer. From the adapter this so/dll can be invoked with JNA (https://github.com/java-native-access/jna)
The NetCDF3 bytes can be passed to the so/dll use System.getProperties().get/put(file) to get/put the bytes of the netcdf file. The Fortran/C code can use the nc_open_mem/nc_create_mem to open/create the bytes
rootDir
Root directory for the external module. Other directories can be defined relative to this rootDir using predefined tags (see comment box below).
workDir
Working directory to be used by the external module. When started this directory will be the current directory.
exportDir
Directory to export data from Delft-FEWS to the external module. All Published Interface files will be written to this directory (unless overruled in naming the specific export files).
exportDataSetDir
Directory to export module datasets from Delft-FEWS to the external module. A module dataset is a ZIP file, which will be unzipped using this directory as the root directory. If the zip file contains full path information, this will be included as a tree of subdirectories under this directory.
updateExportDataSetDirOnlyOnChange
If set to 'true' datasets are only updated when they have changed. Change is detected by comparing the timestamp in the dataset info file with the modification time of the dataset configuration file. By default this value is 'false' and datasets are always updated. Since the 2018.02 the dataset info file is written to $REGION_HOME$/temp/moduleDataSetsCheckSums when the export dir is sub dir (any level) of the region home.
purgeExportDataSetDirOnUpdate
If a dataset has been detected as updated then this option allows user to purge content of existing moduledataset directory before new moduledataset is exported. By default the value is 'false' and all existing dataset content is overwritten.
exportIdMap
ID of the IdMap used to convert internal parameterId's and locationId's to external parameter and location Id's. See section on configuration for Mapping Id's units and flags.
exportUnitConversionsId
Id of UnitConversions to be used for export unit mapping
importDir
Directory to import result data from the external module to Delft-FEWS. All Published Interface files will be read from this directory (unless overruled in naming the specific export files).
importIdMap
ID of the IdMap used to convert external parameterId's and locationId's to internal parameter and location Id's. This may be defined to be the same as the import directory, but may also contain different mappings. See section on configuration for Mapping Id's units and flags.
importUnitConversionsId
Id of UnitConversions to be used for import unit mapping
dumpFileDir
Directory for writing dump files to. Dump Files are created when one of the execute activities fails. A dump file is a ZIP file which includes all the dumpDir directories defined. The dump file is created immediately on failure, meaning that all data and files are available as they are at the time of failure and can be used for analysis purposes. The ZIP file name is time stamped to indicate when it was created.
dumpDir
Directory to be included in the dump file. All contents of the directory will be zipped. Multiple dumpDir's may be defined.
NOTE: ensure that the dumpDir does not include the dumpFileDir. This creates a circular reference and may result in corrupted ZIP files.
diagnosticFile
File name and path of diagnostic files created in running modules. This file should be formatted using the Published Interface diagnostics file specification.
missVal
Optional specification of missing value identifier to be used in PI-XML exported to modules and imported from modules.
NOTE: it is assumed an external module uses the same missing value identification for both import and export data.
convertDatum
Optional Boolean flag to indicate level data is used and produced by the module at a global rather than a local datum. The convention in Delft-FEWS is that data is stored at a local datum. If set to true data in parameter groups supporting datum conversion will be converted on export to the global datum by adding the z coordinate of the location. (see definition of parameters and locations in Regional Configuration).
timeZone
Time zone with reference to UTC (equivalent to GMT) for all time dependent data communicated with the module. If not defined, UTC+0 (GMT) will be used. This time zone is used when importing pi files and the time zone is not available in the pi file.
timeZoneOffset
The offset of the time zone with reference to UTC (equivalent to GMT). Entries should define the number of hours (or fraction of hours) offset. (e.g. +01:00). This time zone is used when importing pi files and the time zone is not available in the pi file.
timeZoneName
Enumeration of supported time zones. See appendix B for list of supported time zones. This time zone is used when importing pi files and the time zone is not available in the pi file.
time0Format
The date time format of the %TIME0% variable and the %CURRENT_The date time format of the %END_DATE_TIME% variable. This date time format is only used if there is no date time format specified in the arguments for the variable. yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute.
startDateTimeFormat
The date time format of the %START The %END_DATE_TIME% variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02).
dateTimeFormat
Since stable build 2015.01. Definitions of date time formats that can be used as arguments for the %TIME0%, %START_DATE_TIME% and %END_DATE_TIME% variables, e.g.: %START_DATE_TIME(idOfADateFormat)% %END_DATE_TIME(idOfAnotherDateFormat)%. Date time formats specified as arguments overrule the startDateTimeFormat and endDateTimeFormat specified above. This date time format is only used if there is no date time format specified in the arguments for the variable. yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute. The %START_DATE_TIME% and %END_DATE_TIME% variables only work variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02).
...
endDateTimeFormat
The date time format
...
of the %END_DATE_TIME% variable. This date time format is only used if there is no date time format specified in the arguments for the variable. yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute.
...
The %END_DATE_TIME% variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02).
dateTimeFormat
Since stable build 2015.01. Definitions of date time formats that can be used as arguments for the %TIME0%, %START_DATE_TIME% and %END_DATE_TIME% variables, e.g.: %START_DATE_TIME(idOfADateFormat)% %END_DATE_TIME(idOfAnotherDateFormat)%. Date time formats specified as arguments overrule the startDateTimeFormat and endDateTimeFormat specified above. The %START_DATE_TIME% and %END_DATE_TIME% variables only work in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02).
- id: Identifier for this date time format. Use this identifier to refer to this date time format in the argument of a variable.
- dateTimePattern: Pattern for this date time format. This can be e.g. "yyyy-MM-dd HH:mm:ss". yyyy = Year, MM = Month in year, dd = Day in month, HH = Hour in day (0-23), mm = Minute in hour, ss = Second in minute.
ensembleMemberCount
Defines if ensembles are read from or written to a number of sub directories.
modelTimeStep
The model time step adjusts the end time when necessary of the run period for this model and for all models/modules that will run aft05GeneralAdapterModule-importShapeFileActivityer this model in the same task run.
Burn-In Profile
Burn-in profile for cold state starts. Used to replace first part of a timeseries.
For time series with matching parameter-location ids, the first value is replaced by the initialValue. Element length defines the length of timeseries beginning that is to be replaced using linear interpolation.
| Code Block |
|---|
ensembleMemberCount
Defines if ensembles are read from or written to a number of sub directories.
modelTimeStep
The model time step adjusts the end time when necessary of the run period for this model and for all models/modules that will run after this model in the same task run.
Burn-In Profile
Burn-in profile for cold state starts. Used to replace first part of a timeseries.
For time series with matching parameter-location ids, the first value is replaced by the initialValue. Element length defines the length of timeseries beginning that is to be replaced using linear interpolation.
| Code Block | |||
|---|---|---|---|
| |||
<burnInProfile>
<length multiplier="4" unit="hour"/>
<timeSeries>
<parameterId>H.obs</parameterId>
<locationSetId>locationInitialValueAttSet</locationSetId>
<initialValueAttributeId>initialValue</initialValueAttributeId>
</timeSeries>
</burnInProfile>
|
...
Filter specifying files to be removed. Wildcards Wild cards may be used.
Deleting a whole directory tree can be achieved by defining the directory path in the filter without any file filter options (.).
name wild cards. eg: %ROOT_DIR%/exportDir/purgeDirectory
Sub directories will not be removed. If the configured directory contains subdirectories it can not be removed, this will result in an error that is logged: "GA.Error: Can not delete an existing directory "
A directory can only be removed if it is a sub directory of the General Adapter root directory!
,
When using a path with a filename wild card, subdirectories will by default not be removed, an optional element, <includeSubdirectories> can be included to also delete subdirectories, including their content.
Please note that it is possible to delete files outside the general adapter root folder, so it is recommended to always start the filter path with %ROOT_DIR% to prevent this from happening accidentally.
Minimum file age can optionally be used to only purge files over a certain age.
Example (note Example (not the use of tags to define the root directory namesname): 
| Code Block |
|---|
unzipActivity
Root element of an unzip activity used to unpack a zip file and put the contained files in the directory of choice. Multiple unzip activities may be defined.
Each activity has the following elements:
| ||||
<startUpActivities>
<purgeActivity>
<filter>%ROOT_DIR%/temp</filter>
</purgeActivity>
<purgeActivity>
<filter>%ROOT_DIR%/logs/*.*</filter>
<minimumFileAge unit="day" multiplier="2"/>
</purgeActivity>
<purgeActivity>
<includeSubdirectories>true</includeSubdirectories>
<filter>%ROOT_DIR%/importDir/*.*</filter>
</purgeActivity>
</startUpActivities> |
unzipActivity
Root element of an unzip activity used to unpack a zip file and put the contained files in the directory of choice. Multiple unzip activities may be defined.
Each activity has the following elements:
- description - optional description of the activity (for documentation only)
- sourceZipFile - the name of the zip file to be unzipped
- description - optional description of the activity (for documentation only)
- sourceZipFile - the name of the zip file to be unzipped
- destinationDir - the name of the directory where the files will be put
zipActivity
Root element of a zip activity used to pack all files and subdirectories of an indicated directory to a zip file for later use/inspection. One or more source file pattern (including * and ? wildcards) can be specified to include only a subset of the files in the source directory. Multiple zip activities may be defined. The file name may include environment variables, as well as tags defined in the general adapter or on the global.properties. See the environment variables section for a list of internal variables.
...
- description - optional description of the activity (for documentation only)
- sourceDir - the name of the directory containing the files to be zipped
- sourcePatterm sourcePattern - (Since 2019.02) a file name pattern to select a subset of the files in source directory. Since 2022.01 tags between %% are recognized
- destinationZipFile - the name of the zip file to be created
...
Example:
| No Format |
|---|
<startupActivities>
<unzipActivity>
<sourceZipFile>extra_files.zip</sourceZipFile>
<destinationDir>%ROOT_DIR%/work</destinationDir>
</unzipActivity>
</startupActivities>
...
<shutdownActivities>
<zipActivity>
<sourceDir>%ROOT_DIR%/work</sourceDir>
<sourcePattern>input/timeseries_input.*</sourcePattern>
<sourcePattern>diagnostics/diag.xml</sourcePattern>
<destinationZipFile>%ROOT_DIR%/inspection/%CURRENT_TIME%_%TIME0%_saved.zip</destinationZipFile>
</zipActivity>
</shutdownActivities>
|
...
- coldState - Root element for defining the stateSelection method to always export a cold state.
- groupId - Id of the group of cold states to be used. This must be a groupId as defined in the ColdModuleInstanceStateGroups configuration (see Regional Configuration).
- coldState:startDate - Definition of the start date of the external module run when using the cold state. This startDate is specified relative to the start time of the forecast run. A positive startDate means it is before the start time of the forecast run.
- coldState:fixedStartTime - (Since 2012_02) the start date can be configured as an fixed time
- warmState - Root element for defining the stateSelection method to search for the most suitable warm state.
- stateSearchPeriod - Definition of the search period to be used in selecting a warm state. The database will return the most recent suitable warm state found within this search period.
- searchForTransientStates - Default is true, and the prefered option for forecast modules. An historical state generating module however should preferably not start with a transient state, which is a state imported after the state search period. Transient states can be given a much lower expiry time (see option below) to reduce the size of the database. See this memo for more background information.
- transientStateExpiryTime - Expiry time of the transient states, which are states with a time after the warm state search period
- coldStateTime - Definition of the start time to use for a cold state if a suitable state is not found within the warm state search period.
- insertColdState - When you set insertColdState to true, the defaultColdState is inserted into the WarmStates when no WarmState is found inside the stateSearchPeriod. By default the cold state is not inserted as warm state
| Code Block | ||||
|---|---|---|---|---|
| ||||
<stateSelection>
<warmState>
<stateSearchPeriod unit="hour" start="-48" end="0"/>
<searchForTransientStates>false</searchForTransientStates>
<transientStateExpiryTime multiplier="1" unit="day"/>
<coldStateTime unit="hour" value="-48"/>
<insertColdState>true</insertColdState>"
</warmState>
<overrulingColdStateModuleInstanceId>ExportStateActivityOverrulingColdState</overrulingColdStateModuleInstanceId>
</stateSelection>
|
...
Includes missing values in the export file or leave them out.
checkMissingValues
In addition, unreliable data will be exported as missing values because unreliable data cannot be used in calculations.
Note: this means that the original values that have been set as unrealiable will be converted to missing upon export. If the original values are needed (in for example a model that does the data validation instead of the FEWS ValidationRuleSets), use the regular exportModule.
checkMissingValues
Option to check the timeseries for missing values. This option Option to check the timeseries for missing values. This option works in combination with the Parameter element 'allowMissing'. If that allowMissing is set to false, you can check for missing values. So if checkMissingValues = true and allowMissing=false, an error will occur in case there are missing values to be exported. As such, you can prevent to run a model with missing values and let the General Adapter stop with an error.
...
Option to skip time series sets if the location set does not exist. Useful when module or workflow is run in loop with tags being translated. Default is 'false'.
exportMapStacksActivity
...
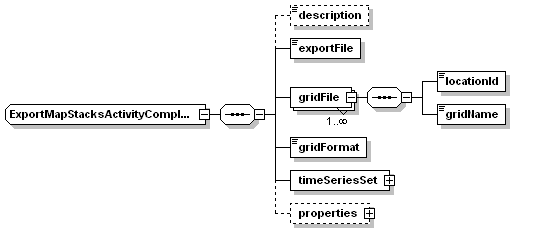
Figure 72 Elements of the ExportMapStacksActivity.
...
TimeSeriesSets to be exported. These should contain only one locationId. For exporting multiple grids, multiple exportMapStack activities should be defined.
Note: when exporting an equidistant timeseriesset, the assumption is that the model adapter uses the start and the timestep to derive the timestamp of the event. Only for non-equidistant timeseriesset, the mapstacks.xml will hold events.
exportProfilesActivity
Configuration of the exportProfiles activity is identical to the exportTimeSeries Activity.
...
Optional reference to overrule a 'normal' moduleDateSet export by a different export in case of a cold state start
See also: Configuration guide - 01 Module Datasets
exportParameterActivity
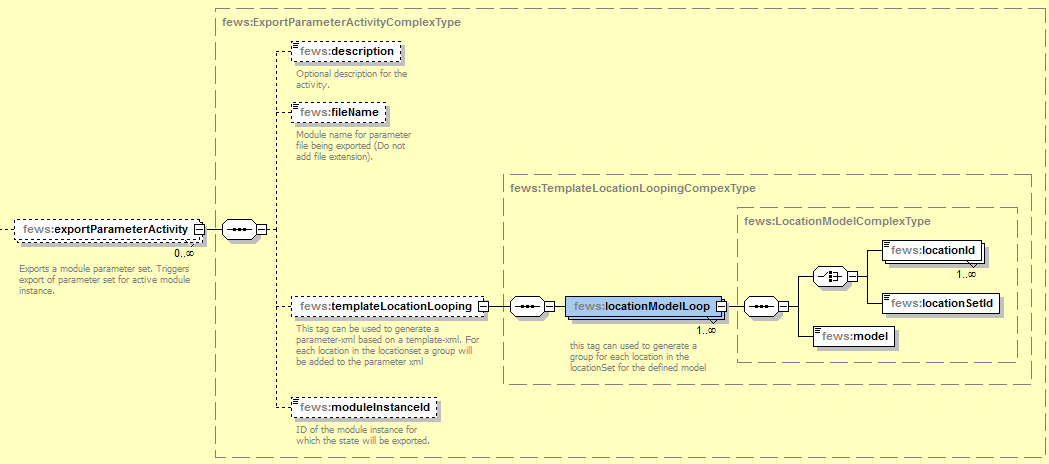
Figure 74 Elements of the exportParameter section
...
exportLocationAttributesCsvActivity (since 2020.01)
Exports location attributes attributes of a location set or a single location to csv format, including multi-value attributes. Skips by default when encountering empty or non-existing location sets.
...
Optional. Default value is netcdf3. Currently supported other option is netcdf4.
writeRealizationDimension
metadata
Since 2023.01 metadata can be added to the netcdf global attributes, just like the implementation for normal netcdf exports.
geoDatum
Optional. To configure reprojection of location coordinates you can specify the required output geodatum here. This option is available only for scalar datasets.
writeRealizationDimension
Applicable only Applicable only to scalar and gridded time series with exactly one ensemble member. When false then this ensemble member is not written to the file and parameter in the file does not have realization dimension. A config error will be given when set to false and multiple ensemble members are found in the timeseries.
...
- string
- int
- float
- double (since stable build 2014.01)
- bool
example of exported run file
| Code Block | ||||
|---|---|---|---|---|
| ||||
<Run xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.wldelft.nl/fews/PI" xsi:schemaLocation="http://www.wldelft.nl/fews/PI http://fews.wldelft.nl/schemas/version1.0/pi-schemas/pi_run.xsd" version="1.5">
<logLevel>info</logLevel>
<timeZone>0.0</timeZone>
<startDateTime date="1900-01-01" time="00:00:00"/>
<endDateTime date="2100-01-01" time="00:00:00"/>
<time0 date="2000-01-01" time="00:00:00"/>
<workDir>workdir</workDir>
<outputDiagnosticFile>diagnostic</outputDiagnosticFile>
</Run>
|
exportNetcdfRunFileActivity (since stable build 2014.01)
...
- string
- int
- float
- double (since stable build 2014.01)
- bool
Additionally it is possible to pass a locationAttribute as a property. This allows passing of location attributes to the netcdfRunFile.
Configuration example
| Code Block | ||||
|---|---|---|---|---|
| ||||
<exportNetcdfRunFileActivity>
<description>This run file is passed as argument to XBeachPreAdapter</description>
<exportFile>run_info.nc</exportFile>
<properties>
<bool key="use_friction" value="true"/>
<locationAttribute key="localModel" locationId="$MODEL$" attributeId="forRunFileExport"/>
</properties>
</exportNetcdfRunFileActivity>
|
...
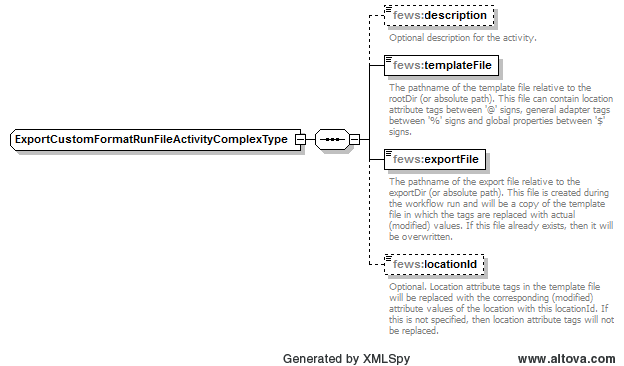
Elements of the ExportCustomFormatRunFileActivity configuration
Note: the application of this feature is deprecated(still) possible, but not recommended. Better use the export(Netcdf)RunFileActivity in combination with a model pre-adapter instead.
...
| Code Block |
|---|
2002 11 30 09 00 ! MODEL START : ISYEAR,ISMONTH,ISDATE,ISHR,ISMN [year,month,day,hour,minute] 2002 11 30 11 00 ! MODEL STOP : ISYEAR,ISMONTH,ISDATE,ISHR,ISMN [year,month,day,hour,minute] 2 ! TIME STEP :[sec] 131-52-2 ! TOXIC ID : CAS NO.-TOXIC, 444#-OI 235875.9 329956.4 ! ACCIDENT LOC. : X Y TM coordinate (referred in LXLY.INP) 2012 01 10 09 00 ! ACCIDENT TIME : IEVYEAR,IEVMONTH,IEVDATE,IEVHR,IEVMN [year,month,day,hour,minute] 10.0 ! spill duration : [MIN] 500000.0 ! spill material mass : [G] 10. ! CHLA : CHLA CONC. [UG/L] FOR TOXIC CALCULATION 5. ! TEM : WATER TEMPERATURE [DEGREE C] FOR TOXIC CALCULATION 5. ! SSC : Suspended Solid Conc. [MG/L] FOR TOXIC CALCULATION 0.1 ! DOC : DOC CONC. [MG/L] FOR TOXIC CALCULATION 100. ! I : IRADIATION [LY/DAY] 5. ! WSPD : WINDSPEED [M/S] 73 ! simulation number 200211300900FSS200211300900 FSS ! test |
exportAreaSelectionActivity
...
In the following example one importCsvModuleRunTablesActivity exportCsvModuleRunTablesActivity is specified for a module run table that was imported earlier using the ModuleInstanceId ImportCsvModuleRunTablesActivity Big10_RiverWare_Big10. As more than one table may have been imported using that module, the Display name of the table is also given as additional selector.
<exportCsvModuleRunTablesActivity>
| Code Block | ||
|---|---|---|
| ||
<exportCsvModuleRunTablesActivity>
<moduleInstanceId>Big10 |
...
_RiverWare_Big10</moduleInstanceId> |
...
<charset>UTF-8</charset>
<description>RCT Tool Csv Module Data Activity Test case.</description>
<exportFile>convergence_ipopt.csv</exportFile>
<displayName>Violated Constraints RBS</displayName>
<onFailWarnAndContinue>true</onFailWarnAndContinue>
...
<charset>UTF-8</charset> <description>RCT Tool Csv Module Data Activity Test case.</description> <exportFile>convergence_ipopt.csv</exportFile> <displayName>Violated Constraints RBS</displayName> <onFailWarnAndContinue>true</onFailWarnAndContinue> </exportCsvModuleRunTablesActivity> |
Execute Activities
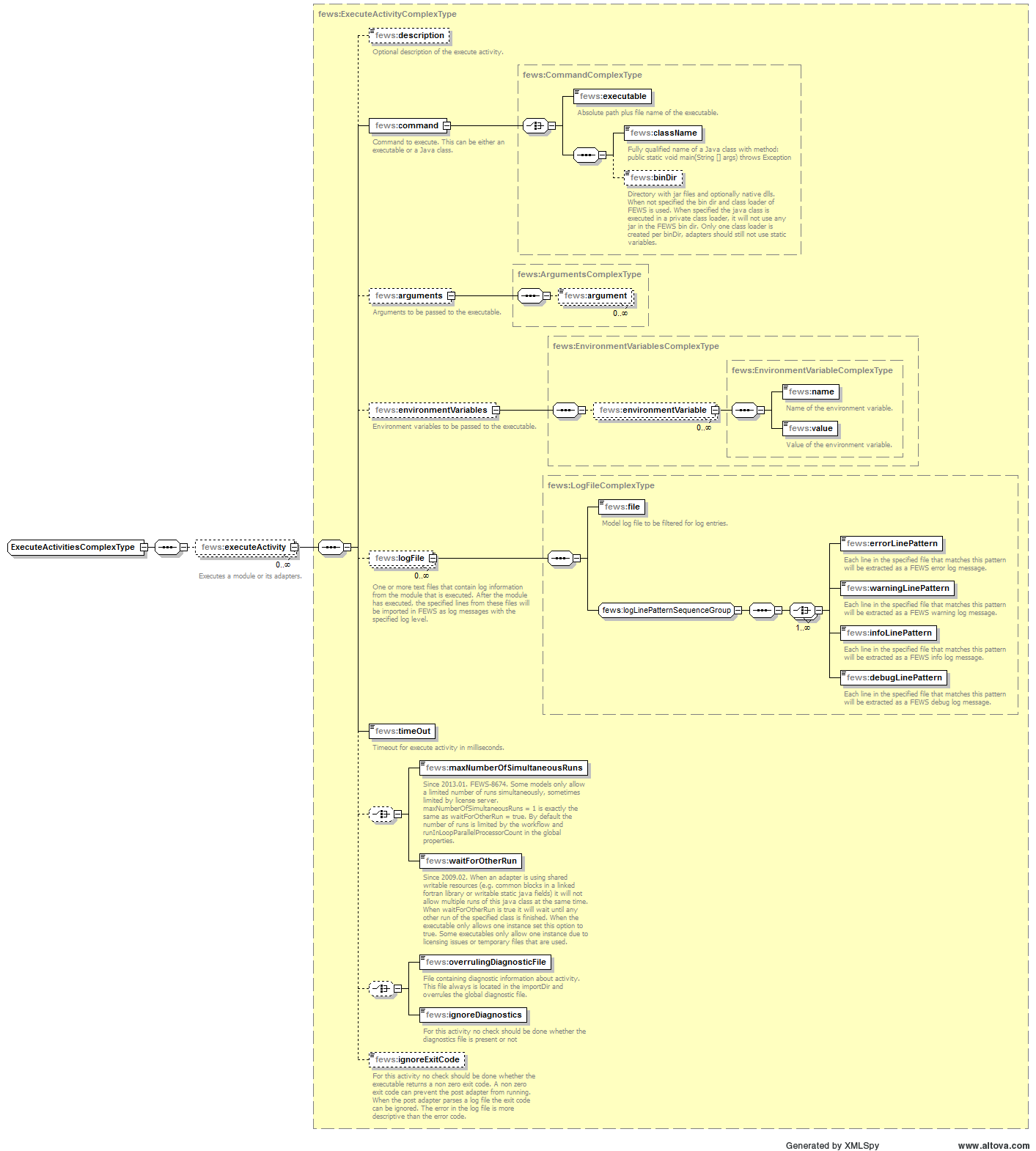
Elements of the ExecuteActivity configuration
...
- executable - File name and location of the executable to run the command is an executable. The file name may include environment variables, as well as tags defined in the general adapter or on the global.properties.console.redirectToLogFile Since 2018.02. Write the console output written by the executable to the specified file.
- className - Name of Java Class to run if the command defined as a Java class. This class may be made available to Delft-FEWS in a separate JAR file in the \Bin directory.
This class can be executed outside FEWS for testing with
bin/windows/Delft-FEWSc.exe -Xmx512m -Djava.library.path=adapterbin -Wclasspath.1=adapterbin\*.jar -Wmain.class=classname arguments - binDir - Optional. Directory with jar files and optionally native dlls. When not specified the bin dir and classloader of FEWS is used. When specified the java class is executed in a private class loader, it will not use any jar in the FEWS bin dir. Only one class loader is created per binDir, adapters should still not use static variables. All dependencies should also be in this configured bin dir.
- moduleDataSetName - Optional. As of 2014.02 it is possible to update the binaries in the binDir using a module data set. The loaded binaries will first be unloaded before the content of the module dataset is unpacked to binDir. Since 2017.01 the binDir will be deleted in order to update it, therefore a restriction has been build in that the binDir should be a sub directory of the region home or named "bin".
- customJreDir - Optional. As of 2016.01 it possible to configure a directory of a specific jre that should be used to run a java class. This could be required for modules that are not compatible with the java version used by FEWS. Or this method could be used to instantiate a separate JVM for the process being executed
- jvmArg - Optional, unbounded and only in combination of customJreDir. Specifies extra jvm arguments for instance -mx512m to give the jvm more memory than the -mx256m that FEWS uses by default for the custom jre.
| Code Block | ||||
|---|---|---|---|---|
| ||||
<command> <className>nl.wldelft.fews.adapter.urbsiniadapter.UrbsIniAdapter</className> <customJreDir>$FEWS<customJreDir>$BIN_BIN_DIR$/windows/jre</customJreDir> <jvmArg>-mx512m</jvmArg> </command> |
arguments
Optional. Root element for defining arguments to be passed to the executable/Java class
- argument - Definition of an argument to be passed to the executable/Java Class
environmentVariables
Optional. Root element for defining environment variables prior to running the executable/Java class
- environmentVariable - Definition of an environment variable prior to running the executable/Java class
- environmentVariable.name - Name of environment variable
- environmentVariable.value - Value of environment variable
For example, to append some directory to the Windows PATH environment variable use:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<environmentVariables>
<environmentVariable>
<name>path</name>
<value>%PATH%;%ROOT_DIR%\wflow_bin;</value>
</environmentVariable>
</environmentVariables> |
logFile
Optional (since stable build 2014.01) . One or more text files that contain log information from the module that is executed. After the module has executed, the specified lines from these files will be imported in FEWS as log messages with the specified log level.
- file - Path and name of a log file to be filtered for log entries. This should be either an absolute path or a path relative to the rootDir defined in the general section.
- errorLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS error log message.
- warningLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS warning log message.
- infoLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS info log message.
- debugLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS debug log message.
- restartWorkflowLinePattern - The first line in the specified file that matches this pattern will restart the complete root workflow (Since 2018.01)
Configuration example:
...
<logFile>
<file>XBerror.txt</file>
<!-- Import every line as a separate FEWS error log message. -->
<errorLinePattern>*</errorLinePattern>
</logFile>
<logFile>
<file>XBwarning.txt</file>
<!-- Import every line that contains "warning" as a separate FEWS info log message. -->
<infoLinePattern>*warning*</infoLinePattern>
</logFile>
<logFile>
<file>XBlog.txt</file>
<!-- Import every line that contains "ERROR" as a separate FEWS debug log message. -->
<debugLinePattern>*ERROR*</debugLinePattern>
</logFile>
console
Element for connecting the console output of the activity to FEWS
- redirectToLogFile: Since 2018.02. Write the console output written by the executable to the specified file.
- restartWorkflowLinePattern: Since 2018.01. As soon the executable writes a line, matching this pattern, to the console the complete workflow is restarted
- maxRestartWorkflowCount: Since 2018.01. Max number of times the workflow is restarted. Default is 2
- progressPattern: Since 2021.02. Pattern to extract a percentage number from a console log line, each line will be checked for the pattern when it comes through. The places of the question marks should contain the value. Will be read as double but written as integer rounded down. Question marks should be at the start or end of the pattern. For instance "progress: ???" When used in combination with "activityDurationWeight" it will be scaled accordingly. For instance when 2 activities are present with a weight of 1, the first progress will be rescaled from 0 to 50 and the second from 50 to 100. The progress of a running task can be viewed in the Running Forecasts tab of the system monitor.
activityDurationWeight
Weight of the activity compared to others, used for tracking progress percentage of the module.
arguments
Optional. Root element for defining arguments to be passed to the executable/Java class
- argument - Definition of an argument to be passed to the executable/Java Class
environmentVariables
Optional. Root element for defining environment variables prior to running the executable/Java class
- environmentVariable - Definition of an environment variable prior to running the executable/Java class
- environmentVariable.name - Name of environment variable
- environmentVariable.value - Value of environment variable
For example, to append some directory to the Windows PATH environment variable use:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<environmentVariables>
<environmentVariable>
<name>path</name>
<value>%PATH%;%ROOT_DIR%\wflow_bin;</value>
</environmentVariable>
</environmentVariables> |
logFile
Optional (since stable build 2014.01) . One or more text files that contain log information from the module that is executed. After the module has executed, the specified lines from these files will be imported in FEWS as log messages with the specified log level.
- file - Path and name of a log file to be filtered for log entries. This should be either an absolute path or a path relative to the rootDir defined in the general section.
- errorLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS error log message.
- warningLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS warning log message.
- infoLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS info log message.
- debugLinePattern - Each line in the specified file that matches this pattern will be extracted as a FEWS debug log message.
- restartWorkflowLinePattern - The first line in the specified file that matches this pattern will restart the complete root workflow (Since 2018.01)
Configuration example:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<logFile>
<file>XBerror.txt</file>
<!-- Import every line as a separate FEWS error log message. -->
<errorLinePattern>*</errorLinePattern>
</logFile>
<logFile>
<file>XBwarning.txt</file>
<!-- Import every line that contains "warning" as a separate FEWS info log message. -->
<infoLinePattern>*warning*</infoLinePattern>
</logFile>
<logFile>
<file>XBlog.txt</file>
<!-- Import every line that contains "ERROR" as a separate FEWS debug log message. -->
<debugLinePattern>*ERROR*</debugLinePattern>
</logFile>
|
timeOut
Timeout to be used when running module (in milliseconds). If run time exceeds timeout it will be terminated and the run considered as having failed.
maxNumberOfSimultaneousRuns
Optional. Since 2013.01. FEWS-8674. Some models only allow a limited number of runs simultaneously, sometimes limited by license server. maxNumberOfSimultaneousRuns = 1 is exactly the same as waitForOtherRun = true. By default the number of runs is limited by the workflow and runInLoopParallelProcessorCount in the global properties.
waitForOtherRun
Optional. Since 2009.02. When an adapter is using shared writable resources (e.g. common blocks in a linked fortran library or writable static java fields) it will not allow multiple runs of this java class at the same time. When waitForOtherRun is true it will wait until any other run of the specified class is finished. When the executable only allows one instance set this option to true. Some executables only allow one instance due to licensing issues or temporary files that are used.
overrulingDiagnosticFile
Optional. File containing diagnostic information about activity. This file always is located in the importDir and overrules the global diagnostic file.
ignoreDiagnostics
Optional. For this activity no check should be done whether the diagnostics file is present or not.
ignoreExitCode
Optional. For this activity no check should be done whether the executable returns a non zero exit code. A non zero exit code can prevent the post adapter from running. When the post adapter parses a log file the exit code can be ignored. The error in the log file is more descriptive than the error code.
Internal GA variables
Several variables are available to be used as an argument to an external program or in the exportCustomFormatRunFileActivity. You can use in any filename or directory the properties from the global.properties file or the next internal variables:
- TEMP_DIR. The %TEMP_DIR% variable is an internal variable which points to a unique temporary directory which is created in the $REGION_HOME$/Temp and which will be removed afterwards.
- ROOT_DIR
- WORK_DIR
- ENSEMBLE_MEMBER_ID
- ENSEMBLE_MEMBER_INDEX
- TIME0
- START_DATE_TIME (the START_DATE_TIME variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02)).
- END_DATE_TIME (the END_DATE_TIME variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02)).
- CURRENT_TIME (since 2015.01)
- TASK_ID
- TASK_RUN_ID: task run ID 'as is' i.e. including a colon
- TASK_RUN_ID_FOR_PATH: similar to TASK_RUN_ID except present tag replaces any special character that may invalidate a file name (for example, a colon or a path separator) by an underscore
- TASK_DESCRIPTION
- TASK_USER_ID
- WHAT_IF_ID (Since 2016.02 build 65440)
- WHAT_IF_ID_FOR_PATH (Since 2022.01 build 110777)
- WHAT_IF_NAME (Since 2016.02 build 69419)
- TIME_ZONE_OFFSET_SECONDS
The colon characters ":" will be replaced by an underscore "_". Use the internal variables with % characters (like %TEMP_DIR%) and the global.properties variables with $ characters (like e.g. $DUMP_DIR$).
| Anchor | ||||
|---|---|---|---|---|
|
| Anchor | ||||
|---|---|---|---|---|
|
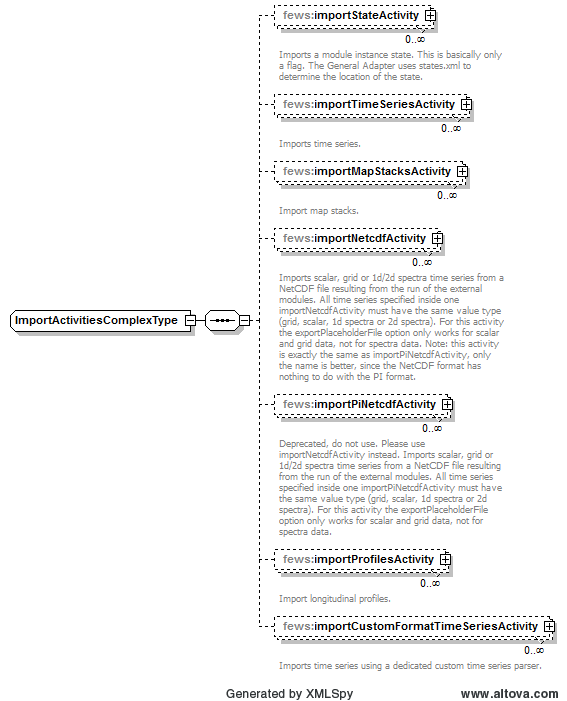
Figure 76 Elements of the ImportActivities configuration
exportPlaceholderFile
| Note |
|---|
Option exportPlaceholderFile is not supported for spectra data. |
This option can be used for all import activities, except for importStateActivity.
If <exportPlaceholderFile>true</exportPlaceholderFile>, then the General adapter will generate placeholder files. A placeholder file is a file with headers only, without timeseries. Its name is the same as the filename configured for the ImportActivity and this placeholderfile is written to the import directory. The placeholder files are written before any execute activity is started. The models cq model adapters should read this placeholder files to see which data should be provided to import in FEWS.
- <importTimeSeriesActivity> writes headers to pi_timeseries.xml
- <importMapStacksActivity> writes headers to pi_mapstacks.xml
- <importNetcdfActivity> writes headers to NetCDF file (only for scalar and grid data, not for spectra data) (It writes the variables as is and does not compact them into smaller types like short or byte like tryCompactingNetCDFData in export module)
- <importProfilesActivity> writes headers to pi_profiles.xml
The intention of this exportPlaceholderFile functionality is that the model cq modeladapter reads the placeholders to see which timeseries are required by FEWS.
After simulation, the model cq modeladapter overwrites these files with its own data over the placeholder files ready to be imported by the import activity.
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importTimeSeriesActivity>
<exportPlaceholderFile>true</exportPlaceholderFile>
<importFile>output.xml</importFile>
<timeSeriesSets>
....
</timeSeriesSets>
</importTimeSeriesActivity>
|
It is available in the same way for importTimeSeriesActivity, importMapStacksActivity, importNetcdfActivity (only for scalar and grid data, not for spectra data) and importProfilesActivity.
description
Optional description of import activity. Used for reference purposes only
importStateActivity

Elements of the ImportStateActivity section.
Root element for importing modules states resulting from the run of the external modules. Multiple elements may be defined. If no state is to be imported (for example in forecast run as opposed to state run), then the element should not be defined.
- description - Optional description for the activity.
- stateConfigFile - Optional, do not use this if a pi state description xml file is not needed. Name (and location) of the PI-XML file describing the states to be imported. This file contains all necessary information to define state type and location. The moduleInstanceId of the state imported is per definition the current module instance. This
timeOut
Timeout to be used when running module (in milliseconds). If run time exceeds timeout it will be terminated and the run considered as having failed.
maxNumberOfSimultaneousRuns
Optional. Since 2013.01. FEWS-8674. Some models only allow a limited number of runs simultaneously, sometimes limited by license server. maxNumberOfSimultaneousRuns = 1 is exactly the same as waitForOtherRun = true. By default the number of runs is limited by the workflow and runInLoopParallelProcessorCount in the global properties.
waitForOtherRun
Optional. Since 2009.02. When an adapter is using shared writable resources (e.g. common blocks in a linked fortran library or writable static java fields) it will not allow multiple runs of this java class at the same time. When waitForOtherRun is true it will wait until any other run of the specified class is finished. When the executable only allows one instance set this option to true. Some executables only allow one instance due to licensing issues or temporary files that are used.
overrulingDiagnosticFile
Optional. File containing diagnostic information about activity. This file always is located in the importDir and overrules the global diagnostic file.
ignoreDiagnostics
Optional. For this activity no check should be done whether the diagnostics file is present or not.
ignoreExitCode
Optional. For this activity no check should be done whether the executable returns a non zero exit code. A non zero exit code can prevent the post adapter from running. When the post adapter parses a log file the exit code can be ignored. The error in the log file is more descriptive than the error code.
Internal GA variables
Several variables are available to be used as an argument to an external program or in the exportCustomFormatRunFileActivity. You can use in any filename or directory the properties from the global.properties file or the next internal variables:
- TEMP_DIR. The %TEMP_DIR% variable is an internal variable which points to a unique temporary directory which is created in the $REGION_HOME$/Temp and which will be removed afterwards.
- ROOT_DIR
- WORK_DIR
- ENSEMBLE_MEMBER_ID
- ENSEMBLE_MEMBER_INDEX
- TIME0
- START_DATE_TIME (the START_DATE_TIME variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02)).
- END_DATE_TIME (the END_DATE_TIME variable only works in an importStateActivity (since 2014.02) and inside a template file for an exportCustomFormatRunFileActivity (since 2013.02)).
- CURRENT_TIME (since 2015.01)
- TASK_ID
- TASK_RUN_ID
- TASK_RUN_ID_FOR_PATH
- TASK_DESCRIPTION
- TASK_USER_ID
- WHAT_IF_ID (Since 2016.02 build 65440)
- WHAT_IF_NAME (Since 2016.02 build 69419)
- TIME_ZONE_OFFSET_SECONDS
The colon characters ":" will be replaced by an underscore "_". Use the internal variables with % characters (like %TEMP_DIR%) and the global.properties variables with $ characters (like e.g. $DUMP_DIR$).
...
Figure 76 Elements of the ImportActivities configuration
exportPlaceholderFile
| Note |
|---|
Option exportPlaceholderFile is not supported for spectra data. |
This option can be used for all import activities, except for importStateActivity.
If <exportPlaceholderFile>true</exportPlaceholderFile>, then the General adapter will generate placeholder files. A placeholder file is a file with headers only, without timeseries. Its name is the same as the filename configured for the ImportActivity and this placeholderfile is written to the import directory. The placeholder files are written before any execute activity is started. The models cq model adapters should read this placeholder files to see which data should be provided to import in FEWS.
- <importTimeSeriesActivity> writes headers to pi_timeseries.xml
- <importMapStacksActivity> writes headers to pi_mapstacks.xml
- <importNetcdfActivity> writes headers to NetCDF file (only for scalar and grid data, not for spectra data) (It writes the variables as is and does not compact them into smaller types like short or byte like tryCompactingNetCDFData in export module)
- <importProfilesActivity> writes headers to pi_profiles.xml
The intention of this exportPlaceholderFile functionality is that the model cq modeladapter reads the placeholders to see which timeseries are required by FEWS.
After simulation, the model cq modeladapter overwrites these files with its own data over the placeholder files ready to be imported by the import activity.
...
<importTimeSeriesActivity>
<exportPlaceholderFile>true</exportPlaceholderFile>
<importFile>output.xml</importFile>
<timeSeriesSets>
....
</timeSeriesSets>
</importTimeSeriesActivity>
It is available in the same way for importTimeSeriesActivity, importMapStacksActivity, importNetcdfActivity (only for scalar and grid data, not for spectra data) and importProfilesActivity.
description
Optional description of import activity. Used for reference purposes only
importStateActivity
Elements of the ImportStateActivity section.
Root element for importing modules states resulting from the run of the external modules. Multiple elements may be defined. If no state is to be imported (for example in forecast run as opposed to state run), then the element should not be defined.
- description - Optional description for the activity.
- stateConfigFile - Optional, do not use this if a pi state description xml file is not needed. Name (and location) of the PI-XML file describing the states to be imported. This file contains all necessary information to define state type and location. The moduleInstanceId of the state imported is per definition the current module instance. This should be either an absolute path or a path relative to the importDir defined in the general section. This option reads the output state file paths from a pi state description xml file.
- stateImportDir - Optional state import directory. This should be either an absolute path or a path relative to the importDir defined in the general section. If this stateImportDir is specified, then the importFile paths in this activity can be paths relative to this stateImportDir instead of absolute paths. This stateImportDir is only needed when you want to use relative importFile paths. If all importFile paths in this activity are absolute, then this stateImportDir is not needed and will not be used. This option does not use a pi state description xml file.
- stateFile - One or more output state files from the model. The specified files will be imported. This option does not use a pi state description xml file.
- importFile - Path and name of an output state file from the model. This file will be imported. This should be either an absolute path or a path relative to the stateImportDir importDir defined in this activity. The %END_DATE_TIME% tag can be used here (since 2014.02), in case the state file name contains a timestamp of the end time of the run.
- relativeExportFile - This relative path and name are used to store the imported file in FEWS. This path should be relative to the stateExportDir in the exportStateActivity that will be used to export this state file again for a future model run. If the imported output state file needs to be renamed before it can be used as input state file for a future model run, then the name of the relativeExportFile can be different from the name of the importFile. The %END_DATE_TIME% tag can be used here (since 2014.02), in case the state file name contains a timestamp of the end time of the run.
- compressedStateLocation - Optional. By default the warm state is zipped and stored as a blob in the database. For large states (>50MB) it is recommended to store the data outside the database in a directory. This directory is configured in the clientConfig.xml (optional element warmStatesDirectory). When using a stand alone system or using oracle and a single MC system it is possible to store larger grids inside the database. Expired states are removed automatically from this directory by the CompactCacheFiles workflow. The state description is still written to the database, the blob field will be empty.
- expiryTime - Optional. When the state is an intermediate result in a forecast run you can make the state expire. By default the expiry time is the same as for the module instance run.
- synchLevel - Optional synch level for state. Defaults to 0 is not specified (i.e. same as data generated by the forecast run)
Configuration example:
New example that does not use a pi state description xml file. In this case, the output state file paths are configured directly in the importStateActivity as absolute paths:
...
<importStateActivity>
<stateFile>
<importFile>%WORK_DIR%/state.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state.inp</relativeExportFile>
</stateFile>
<stateFile>
<importFile>%WORK_DIR%/state2.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state2.inp</relativeExportFile>
</stateFile>
</importStateActivity>
- the general section. This option reads the output state file paths from a pi state description xml file.
- stateImportDir - Optional state import directory. This should be either an absolute path or a path relative to the importDir defined in the general section. If this stateImportDir is specified, then the importFile paths in this activity can be paths relative to this stateImportDir instead of absolute paths. This stateImportDir is only needed when you want to use relative importFile paths. If all importFile paths in this activity are absolute, then this stateImportDir is not needed and will not be used. This option does not use a pi state description xml file.
- stateFile - One or more output state files from the model. The specified files will be imported. This option does not use a pi state description xml file.
- importFile - Path and name of an output state file from the model. This file will be imported. This should be either an absolute path or a path relative to the stateImportDir defined in this activity. The %END_DATE_TIME% tag can be used here (since 2014.02), in case the state file name contains a timestamp of the end time of the run. Important: the state time will be saved at the time of the last timesteps exported from the GA. For example, if you want the state to be saved at T0 but you export a timeseries from the GA which is exceeds T0, the time at which the state is saved will be the last available timestamp in that particular timeseries. Use the <ignoreRunPeriod> option the export timeseries activity to ignore timeseries to be included in the check at which time the state is saved!
- relativeExportFile - This relative path and name are used to store the imported file in FEWS. This path should be relative to the stateExportDir in the exportStateActivity that will be used to export this state file again for a future model run. If the imported output state file needs to be renamed before it can be used as input state file for a future model run, then the name of the relativeExportFile can be different from the name of the importFile. The %END_DATE_TIME% tag can be used here (since 2014.02), in case the state file name contains a timestamp of the end time of the run.
- compressedStateLocation - Optional. By default the warm state is zipped and stored as a blob in the database. For large states (>50MB) it is recommended to store the data outside the database in a directory. This directory is configured in the clientConfig.xml (optional element warmStatesDirectory). When using a stand alone system or using oracle and a single MC system it is possible to store larger grids inside the database. Expired states are removed automatically from this directory by the CompactCacheFiles workflow. The state description is still written to the database, the blob field will be empty.
- expiryTime - Optional. When the state is an intermediate result in a forecast run you can make the state expire. By default the expiry time is the same as for the module instance run.
- synchLevel - Optional synch level for state. Defaults to 0 is not specified (i.e. same as data generated by the forecast run)
Configuration example:
New example that does not use a pi state description xml file. In this case, the output state file paths are configured directly in the importStateActivity as absolute paths:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importStateActivity>
<stateFile>
<importFile>%WORK_DIR%/state.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state.inp</relativeExportFile>
</stateFile>
<stateFile>
<importFile>%WORK_DIR%/state2.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state2.inp</relativeExportFile>
</stateFile>
</importStateActivity>
|
New example that does not use a pi state description xml file. In this case, the output state file paths are configured directly in the importStateActivity as paths relative to a stateImportDir
New example that does not use a pi state description xml file. In this case, the output state file paths are configured directly in the importStateActivity as paths relative to a stateImportDir:
...
<importStateActivity>
<stateImportDir>%WORK_DIR%</stateImportDir>
<stateFile>
<importFile>state.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state.inp</relativeExportFile>
</stateFile>
<stateFile>
<importFile>state2.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state2.inp</relativeExportFile>
</stateFile>
</importStateActivity>
Since 2017.02. Import a dynamic number of states for different state times at once. Pi state description xml file is not used. When exported the file is named "start.bin":
...
<importStateActivity>
<stateImportDir>states</stateImportDir>
<stateFileDateTimePattern>'state'yyyyMMddHHmm'.bin'</stateFileDateTimePattern>
<relativeExportFile>start.bin</relativeExportFile>
</importStateActivity>
Old example that reads the input state file paths from a pi state description xml file. Do not use this if a pi state description xml file is not needed:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importStateActivity>
<stateConfigFile>pi_output_state_description.xml</stateConfigFile>
</importStateActivity> |
Example of a client config for stand alone when importing to the warm states directory. The meta data is still stored in the data base. Files in this directory that don't have meta data will be automatically deleted by the rolling barrel.
...
<clientConfiguration xmlns="http://www.wldelft.nl/fews" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.wldelft.nl/fews http://fews.wldelft.nl/schemas/version1.0/clientConfig.xsd">
<localDataStoreFormat>Firebird</localDataStoreFormat>
<warmStatesDirectory>%REGION_HOME%/warmStates</warmStatesDirectory>
</clientConfiguration>importTimeSeriesActivity
Root element for importing scalar and polygon time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
- importFile - PI-XML file describing the time series to be imported. The file contains all information on type of data to be imported (scalar, longitudinal, grid, polygon). For all data types except the grid the file also contains the time series data If the directory location is not explicitly specified the file will be expected to be read from the importDir defined in the general section.
importMapStacksActivity
Root element for importing grid time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
importNetcdfActivity
Imports scalar, grid or 1d/2d spectra time series from a NetCDF file resulting from the run of the external modules. All time series specified inside one importNetcdfActivity must have the same value type (grid, scalar, 1d spectra or 2d spectra). For this activity the exportPlaceholderFile option only works for scalar and grid data, not for spectra data. Note: this activity is exactly the same as importPiNetcdfActivity, only the name is better, since the NetCDF format has nothing to do with the PI format.
- maximumSnapDistance Since 2014.01. FEWS-10771. Optional maximum horizontal snap distance in meters. When the parser provides horizontal location coordinates (x,y) and no locationIds, then the location mapping will be done by matching the horizontal coordinates. The horizontal snap distance is the tolerance used to detect which internal and external horizontal coordinates are the same. This only works when the input format provides the coordinate system for the coordinates of the locations. When the parser does not provide the coordinates for a time series an error is logged. Note: this option has no effect for grid data. Note 2: it is not possible to import data using horizontal coordinates and using locationIds in the same importNetcdfActivity, need to define separate import activities for that (one with maximumSnapDistance and one without maximumSnapDistance).
- maximumVerticalSnapDistance Since 2014.02. Optional maximum vertical snap distance in meters. When the parser provides vertical location coordinates (z) and no locationIds, then the location mapping will be done by matching the vertical coordinates. The vertical snap distance is the tolerance used to detect which internal and external vertical coordinates are the same. This only works when the input format provides the coordinates of the locations. When the parser does not provide the vertical coordinates for a time series an error is logged. Note: this option currently only works for importing horizontal layers from netcdf 3D grid data. Note 2: it is not possible to import data with z-coordinates (layers from 3D grids) and data without z-coordinates (2D grids) in the same importNetcdfActivity, need to define separate import activities for that (one with maximumVerticalSnapDistance and one without maximumVerticalSnapDistance).
- startWhileRunningExecuteActivities Default is false. If this is true, then this importActivity will run continuously during the configured execute activities. Additionally this importActivity will also run as part of the configured import activities as normal. This way it is possible to import data that is produced by an execute activity, while it is being produced. For instance if a model run writes new output data to an existing file after each timeStep, then the continuously running importActivity will immediately import the file, including the new data. This way the new data can be viewed in FEWS as soon as it becomes available, i.e. already during the model run. Currently the data that is imported during the execute activities can only be viewed after selecting "open most recent running forecast and adjust system time" from the debug menu in the FEWS Explorer window. If the running forecast is opened and selected in the data viewer, then the displays are updated each time when new data becomes available during the run. This feature only has effect for stand alone FEWS systems and for FEWS systems that use direct database access.
Combined with workflow ensemble loop
When an importNetcdfActivity is run within an ensemble loop defined in the workflow configuration and the %ENSEMBLE_MEMBER_ID% tag is used in the <importDir> or the <importFile> it will loop over the ensemble members and use the ensemble member index for the imported scalar time series (since 2017.02).
...
<activity>
<moduleInstanceId>ImportNetcdfScalarEnsembles</moduleInstanceId>
<ensemble>
<ensembleId>Ens</ensembleId>
<ensembleMemberIndexRange start="0" end="4"/>
<runInLoop>false</runInLoop>
</ensemble>
</activity><stateImportDir>%WORK_DIR%</stateImportDir>
<stateFile>
<importFile>state.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state.inp</relativeExportFile>
</stateFile>
<stateFile>
<importFile>state2.out</importFile>
<!-- Rename imported state file so that it can be used as input state for a future model run. -->
<relativeExportFile>state2.inp</relativeExportFile>
</stateFile>
</importStateActivity>
|
Since 2017.02. Import a dynamic number of states for different state times at once. Pi state description xml file is not used. When exported the file is named "start.bin":
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importStateActivity>
<stateImportDir>states</stateImportDir>
<stateFileDateTimePattern>'state'yyyyMMddHHmm'.bin'</stateFileDateTimePattern>
<relativeExportFile>start.bin</relativeExportFile>
</importStateActivity>
|
Old example that reads the input state file paths from a pi state description xml file. Do not use this if a pi state description xml file is not needed:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importStateActivity>
<stateConfigFile>pi_output_state_description.xml</stateConfigFile>
</importStateActivity> |
Example of a client config for stand alone when importing to the warm states directory. The meta data is still stored in the data base. Files in this directory that don't have meta data will be automatically deleted by the rolling barrel.
| Code Block | ||||
|---|---|---|---|---|
| ||||
<clientConfiguration xmlns="http://www.wldelft.nl/fews" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.wldelft.nl/fews http://fews.wldelft.nl/schemas/version1.0/clientConfig.xsd">
<localDataStoreFormat>Firebird</localDataStoreFormat>
<warmStatesDirectory>%REGION_HOME%/warmStates</warmStatesDirectory>
</clientConfiguration> |
importTimeSeriesActivity
Root element for importing scalar and polygon time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
- importFile - PI-XML file describing the time series to be imported. The file contains all information on type of data to be imported (scalar, longitudinal, grid, polygon). For all data types except the grid the file also contains the time series data If the directory location is not explicitly specified the file will be expected to be read from the importDir defined in the general section.
importMapStacksActivity
Root element for importing grid time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
importNetcdfActivity
Imports scalar, grid or 1d/2d spectra time series from a NetCDF file resulting from the run of the external modules. All time series specified inside one importNetcdfActivity must have the same value type (grid, scalar, 1d spectra or 2d spectra). For this activity the exportPlaceholderFile option only works for scalar and grid data, not for spectra data. Note: this activity is exactly the same as importPiNetcdfActivity, only the name is better, since the NetCDF format has nothing to do with the PI format.
- maximumSnapDistance Since 2014.01. FEWS-10771. Optional maximum horizontal snap distance in meters. When the parser provides horizontal location coordinates (x,y) and no locationIds, then the location mapping will be done by matching the horizontal coordinates. The horizontal snap distance is the tolerance used to detect which internal and external horizontal coordinates are the same. This only works when the input format provides the coordinate system for the coordinates of the locations. When the parser does not provide the coordinates for a time series an error is logged. Note: this option has no effect for grid data. Note 2: it is not possible to import data using horizontal coordinates and using locationIds in the same importNetcdfActivity, need to define separate import activities for that (one with maximumSnapDistance and one without maximumSnapDistance).
- maximumVerticalSnapDistance Since 2014.02. Optional maximum vertical snap distance in meters. When the parser provides vertical location coordinates (z) and no locationIds, then the location mapping will be done by matching the vertical coordinates. The vertical snap distance is the tolerance used to detect which internal and external vertical coordinates are the same. This only works when the input format provides the coordinates of the locations. When the parser does not provide the vertical coordinates for a time series an error is logged. Note: this option currently only works for importing horizontal layers from netcdf 3D grid data. Note 2: it is not possible to import data with z-coordinates (layers from 3D grids) and data without z-coordinates (2D grids) in the same importNetcdfActivity, need to define separate import activities for that (one with maximumVerticalSnapDistance and one without maximumVerticalSnapDistance).
- startWhileRunningExecuteActivities Default is false. If this is true, then this importActivity will run continuously during the configured execute activities. Additionally this importActivity will also run as part of the configured import activities as normal. This way it is possible to import data that is produced by an execute activity, while it is being produced. For instance if a model run writes new output data to an existing file after each timeStep, then the continuously running importActivity will immediately import the file, including the new data. This way the new data can be viewed in FEWS as soon as it becomes available, i.e. already during the model run. Currently the data that is imported during the execute activities can only be viewed after selecting "open most recent running forecast and adjust system time" from the debug menu in the FEWS Explorer window. If the running forecast is opened and selected in the data viewer, then the displays are updated each time when new data becomes available during the run. This feature only has effect for stand alone FEWS systems and for FEWS systems that use direct database access.
import multiple files at once
- folder Import all file in the specified folder.
- fileNamePatternFilter Only import files that match the pattern. (e.g. *.nc)
- fileNameLocationIdPattern. Since 2023.02. Regular Expression. When a match of the pattern in the filename is found, this will overrule the external grid location Id for the time series being imported A simple pattern is (.*) which matches the whole filename. (.*)\.nc extracts the file name without the .nc extension. An other simple pattern is .{2}(.*).{4} that removes the first 2 and last 4 character of the filename to get the id More complicated expressions can be found at http://en.wikipedia.org/wiki/Regular_expression
| Code Block | ||||
|---|---|---|---|---|
| ||||
<importNetcdfActivity>
<folder>%ROOT_DIR%/importDir</folder>
<fileNamePatternFilter>*.nc</fileNamePatternFilter>
<fileNameLocationIdPattern>(.*)\.nc</fileNameLocationIdPattern>
<timeSeriesSets>
<timeSeriesSet>
<moduleInstanceId>GeneralAdapterRun</moduleInstanceId>
<valueType>scalar</valueType>
<parameterId>WaterLevel</parameterId>
<locationId>H-2001</locationId>
<timeSeriesType>external historical</timeSeriesType>
<timeStep unit="minute" divider="1" multiplier="15"/>
<readWriteMode>add originals</readWriteMode>
<ensembleId>prognose</ensembleId>
</timeSeriesSet>
</timeSeriesSets>
<ignoreNonExistingLocationSets>true</ignoreNonExistingLocationSets>
</importNetcdfActivity> |
Combined with workflow ensemble loop
When an importNetcdfActivity is run within an ensemble loop defined in the workflow configuration and the %ENSEMBLE_MEMBER_ID% tag is used in the <importDir> or the <importFile> it will loop over the ensemble members and use the ensemble member index for the imported scalar time series (since 2017.02).
| Code Block | ||||
|---|---|---|---|---|
| ||||
<activity>
<moduleInstanceId>ImportNetcdfScalarEnsembles</moduleInstanceId>
<ensemble>
<ensembleId>Ens</ensembleId>
<ensembleMemberIndexRange start="0" end="4"/>
<runInLoop>false</runInLoop>
</ensemble>
</activity> |
When it is not desired that all other activities are also run for each ensemble member, make sure <runInLoop> is set to false.
This is useful when 1 general adapter run generates many similar ensemble files that do not contain data from which their ensemble id can be determined besides their file name or their parent directories. Like a run from OpenDA.
importPiNetcdfActivity
Deprecated, do not use. Please use importNetcdfActivity instead. Imports scalar, grid or 1d/2d spectra time series from a NetCDF file resulting from the run of the external modules. All time series specified inside one importPiNetcdfActivity must have the same value type (grid, scalar, 1d spectra or 2d spectra). For this activity the exportPlaceholderFile option only works for scalar and grid data, not for spectra data. For more documentation see importNetcdfActivity.
importProfilesActivity
Root element for importing longitudinal profile time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
Optional description of import activity. Used for reference purposes only
importShapeFileActivity
Root element for importing shape files resulting from the run of the external modules.
A <shapeFileImportDir> can be defined which is either relative (to the general <importDir>) or absolute. When it is not defined the general <importDir> will be used. If the defined directory does not exist, an exception will be thrown. The import directory can be empty.
A <fileDateTimePattern> should be defined to filter out the shape files that need to be imported and to extract the time for the shape in the time series. If the directory is not empty, but none of the files match the defined pattern, an exception will be thrown. Since 2023.01 the fileDateTimePattern is optional. When there is no fileDateTimePattern the *.shp file in the import directory will be imported. The time zero is used as time stamp. Only one shp-file should exist in the import directory. Files without the shp/dbf extension are ignored
A <geoDatum> can be defined if the shape file is not in WGS84. When this is defined, a conversion to WGS84 will take place before storing the time series into the database.
The <timeSeriesSet> will automatically be used for the imported shape, no idmapping will take place.
| Code Block | ||
|---|---|---|
| ||
<importActivities>
<importShapeFileActivity>
<shapeFileImportDir>importshapefileactivityimportdir</shapeFileImportDir>
<fileDateTimePattern>'ImportShapeFileActivity_'ddMMMyyyyHHmmss'.shp'</fileDateTimePattern>
<geoDatum>$GEODATUM$</geoDatum>
<timeSeriesSet>
<moduleInstanceId>ImportActivityNoneEquidistantProfile</moduleInstanceId>
<valueType>polygon</valueType>
<parameterId>H.obs</parameterId>
<locationId>SX.E7842</locationId>
<timeSeriesType>external historical</timeSeriesType>
<timeStep unit="nonequidistant"/>
<relativeViewPeriod unit="hour" start="0" end="2"/>
<readWriteMode>read only</readWriteMode>
</timeSeriesSet>
</importShapeFileActivity>
</importActivities>
|
The attributes (dbf file columns) can be imported by configuring the attributes to import. The attributes are store as time series properties. Only the first row of the dbf file will be imported.
| Code Block | ||
|---|---|---|
| ||
<importActivities>
<importShapeFileActivity>
<shapeFileImportDir>importshapefileactivityimportdir</shapeFileImportDir>
<fileDateTimePattern>'ImportShapeFileActivity_'ddMMMyyyyHHmmss |
When it is not desired that all other activities are also run for each ensemble member, make sure <runInLoop> is set to false.
This is useful when 1 general adapter run generates many similar ensemble files that do not contain data from which their ensemble id can be determined besides their file name or their parent directories. Like a run from OpenDA.
importPiNetcdfActivity
Deprecated, do not use. Please use importNetcdfActivity instead. Imports scalar, grid or 1d/2d spectra time series from a NetCDF file resulting from the run of the external modules. All time series specified inside one importPiNetcdfActivity must have the same value type (grid, scalar, 1d spectra or 2d spectra). For this activity the exportPlaceholderFile option only works for scalar and grid data, not for spectra data. For more documentation see importNetcdfActivity.
importProfilesActivity
Root element for importing longitudinal profile time series resulting from the run of the external modules. Multiple elements may be defined. importFile and timeSeriesSet should be defined.
Optional description of import activity. Used for reference purposes only
importShapeFileActivity
Root element for importing shape files resulting from the run of the external modules.
A <shapeFileImportDir> can be defined which is either relative (to the general <importDir>) or absolute. When it is not defined the general <importDir> will be used. If the defined directory does not exist, an exception will be thrown. The import directory can be empty.
A <fileDateTimePattern> should be defined to filter out the shape files that need to be imported and to extract the time for the shape in the time series. If the directory is not empty, but none of the files match the defined pattern, an exception will be thrown.
A <geoDatum> can be defined if the shape file is not in WGS84. When this is defined, a conversion to WGS84 will take place before storing the time series into the database.
The <timeSeriesSet> will automatically be used for the imported shape, no idmapping will take place.
| Code Block | ||
|---|---|---|
| ||
<importActivities> <importShapeFileActivity> <shapeFileImportDir>import</shapeFileImportDir> <fileDateTimePattern>'ImportShapeFileActivity_'dd MMM yyyy HH mm ss'.shp'</fileDateTimePattern> <geoDatum>$GEODATUM$</geoDatum> <geoDatum>EPSG:102736</geoDatum><charset>ISO-8859-1</charset> <timeSeriesSet><shapeFileAttribute attributeId="Range Min" propertyKey="Min"/> <shapeFileAttribute attributeId="Range Max" propertyKey="Max"/> <timeSeriesSet> <moduleInstanceId>ImportShapeActivity<<moduleInstanceId>ImportActivityNoneEquidistantProfile</moduleInstanceId> <valueType>polygon</valueType> <parameterId>par<<parameterId>H.obs</parameterId> <locationId>Polygon<<locationId>SX.E7842</locationId> <timeSeriesType>external historical</timeSeriesType> <timeStep unit="nonequidistant"/> <relativeViewPeriod unit="hour" start="0" end="2"/> <readWriteMode>read only</readWriteMode> </timeSeriesSet> </importShapeFileActivity> </importActivities> |
The (placeholder) location used for this polygon is defined in Locations.xls in the same way you define a placeholder location for a grid.
...